











MongoDB7.0--SpringBoot聚合操作
摘要
-
本文介绍如何使用SpringBoot实现MongoDB7.0的聚合操作
-
SpringBoot版本3.2.3,MongoDB版本7.0.6
- MongoDB7.0--SpringBoot单集合操作
聚合操作简介
-
聚合操作允许用户处理多个文档并返回计算结果
-
聚合操作包含三类
- 单文档聚合:针对单个集合,如:
db.collection.countDocument(),db.collection.distinct() - 聚合管道:它可以作用在一个或几个集合上,对集合中的数据进行的一系列运算,并将这些数据转化为用户期望的形式,本文主要介绍管道操作
- MapReduce:从MongoDB 5.0开始,map-reduce操作已被弃用,本文不做介绍。
- 单文档聚合:针对单个集合,如:
聚合管道
-
聚合管道是MongoDB中非常强大的功能,它允许用户将多个操作组合在一起,以实现复杂的数据处理。
-
从效果而言,聚合管道相当于 SQL 查询中的 GROUP BY、 LEFT OUTER JOIN 、 AS等。
-
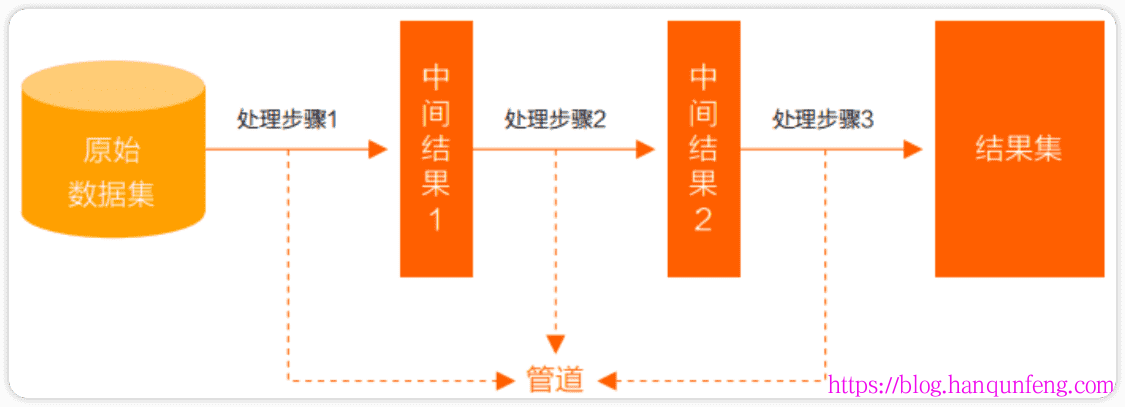
整个聚合运算过程称为管道(Pipeline),它是由多个阶段(Stage)组成的, 每个管道:
- 接受一系列文档(原始数据)
- 每个阶段对这些文档进行一系列运算
- 结果文档输出给下一个阶段
-
聚合管道操作语法
- pipelines 一组数据聚合阶段。除out、Merge和$geonear阶段之外,每个阶段都可以在管道中出现多次。
- options 可选,聚合操作的其他参数。包含:查询计划、是否使用临时文件、 游标、最大操作时间、读写策略、强制索引等等
1
2pipeline = [$stage1, $stage2, ...$stageN];
db.collection.aggregate(pipeline, {options})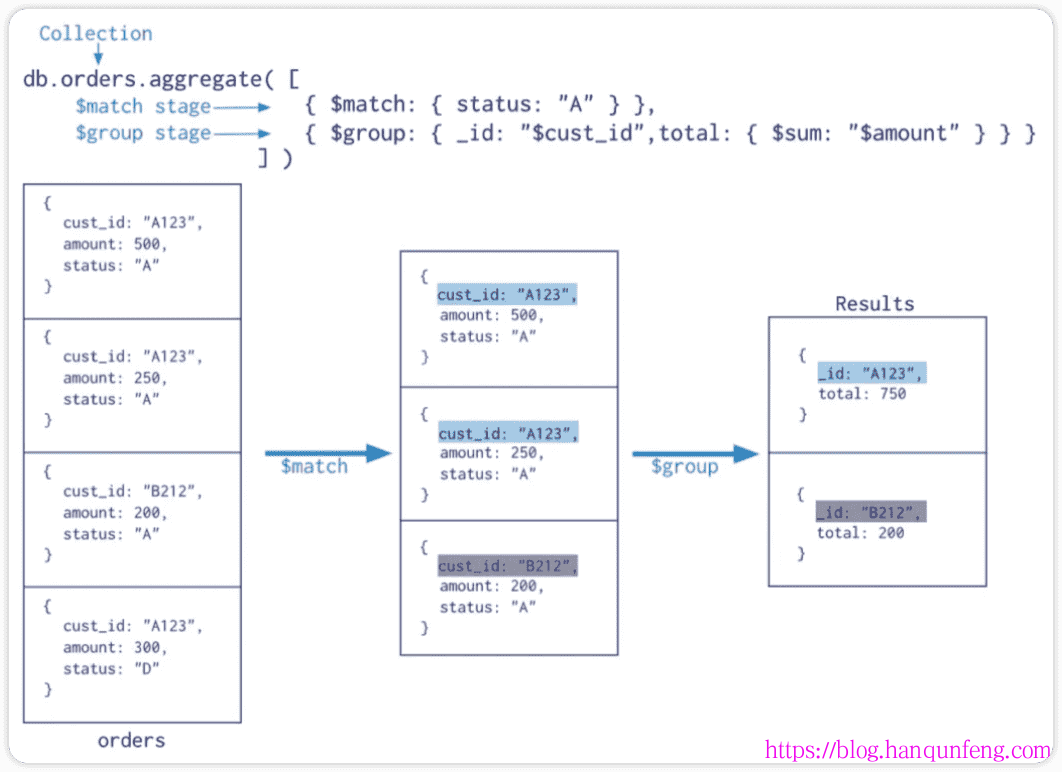
-
常用的聚合阶段运算符
| 阶段运算符 | 描述 | SQL等价运算符 |
|---|---|---|
| $match | 过滤文档 | WHERE |
| $project | 投影,改变文档的形状和内容 | SELECT filedName AS newName |
| $group | 将文档分组 | GROUP BY |
| $sort | 对文档进行排序 | ORDER BY |
| $limit | 限制结果集的大小 | LIMIT |
| $skip | 跳过指定数量的文档 | OFFSET |
| $unwind | 展开数组 | - |
| $lookup | 从其他集合中获取相关文档,左外连接 | LEFT OUTER JOIN |
| $out | 将结果集输出到新的集合 | - |
| $geoNear | 按照地理位置附近的顺序返回文档 | - |
| $graphLookup | 执行递归查询 | - |
| $addFields | 添加新字段 | - |
| $bucket | 根据指定条件将文档分组成桶 | - |
| $facet | 允许在单个聚合阶段内执行多个独立的子聚合 | - |

-
聚合表达式
获取字段信息
1 | $<field> : 用 $ 指示字段路径 |
常量表达式
1 | $literal :<value> : 指示常量 <value> |
系统变量表达式
1 | $$<variable> 使用 $$ 指示系统变量 |
聚合管道示例
-
本示例使用SpringBoot实现MongoDB7.0的聚合操作
-
初始化数据
1 | /* |
$project:投影操作
-
将原始字段投影成指定名称, 如将集合中的 title 投影成 name
1 | // db.books.aggregate([{$project:{name:"$title"}}]) |
-
剔除不需要的字段
1 | // db.books.aggregate([{$project:{name:"$title",_id:0,type:1,author.name:1}}]) |
$match:过滤操作
-
过滤出指定条件的文档
1 | // db.books.aggregate([{$match:{type:"technology"}}]) |
-
组合其它管道
1 | /* |
$count:计数操作
1 | /* |
$group:分组操作
-
按指定的表达式对文档进行分组,并将每个不同分组的文档输出到下一个阶段。输出文档包含一个_id字段,该字段按键包含不同的组。
-
输出文档还可以包含计算字段,该字段保存由$group的_id字段分组的一些accumulator表达式的值。 $group不会输出具体的文档而只是统计信息。
-
语法
1 | { $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } } |
-
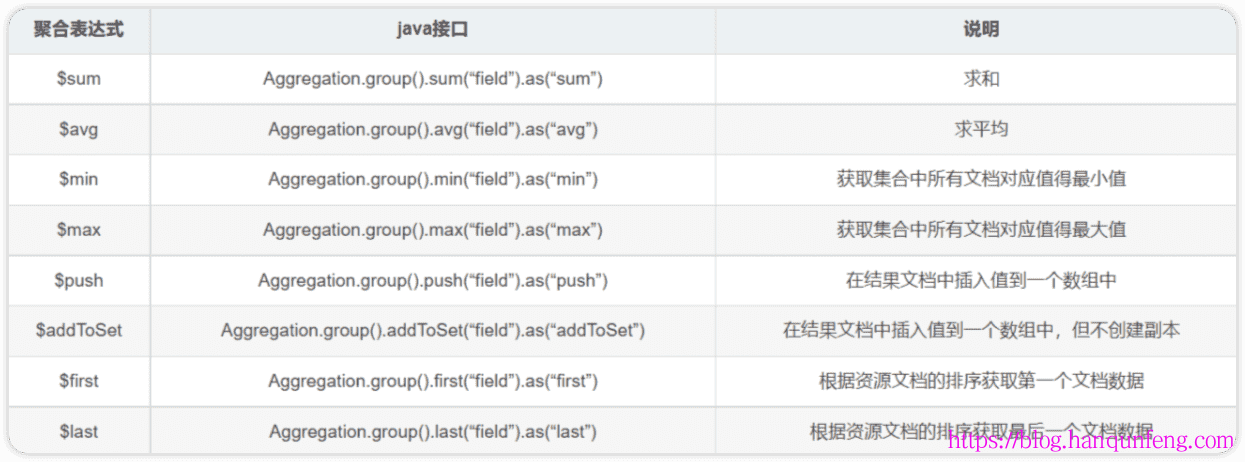
accumulator操作符
| 名称 | 描述 | 类比sql |
|---|---|---|
avg |
计算均值 | avg |
first |
返回每组第一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序的第一个文档。 | limit 0,1 |
last |
返回每组最后一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序的最后个文档。 | - |
max |
根据分组,获取集合中所有文档对应值得最大值。 | max |
min |
根据分组,获取集合中所有文档对应值得最小值。 | min |
push |
将指定的表达式的值添加到一个数组中。 | - |
addToSet |
将表达式的值添加到一个集合中(无重复值,无序)。 | - |
sum |
计算总和 | sum |
stdDevPop |
返回输入值的总体标准偏差(population standard deviation) | - |
stdDevSamp |
返回输入值的样本标准偏差(the sample standard deviation) | - |
示例
-
book的数量,收藏总数和平均值
1 | /* |
-
统计每个作者的book收藏总数
1 | /* |
-
统计每个作者的每本book的收藏数
1 | /* |
-
每个作者的book的type合集
1 | /* |
$unwind
-
可以将数组拆分为单独的文档
-
语法
1 | { |
示例
-
姓名为xx006的作者的book的tag数组拆分为多个文档
1 | /* |
-
使用
includeArrayIndex选项来输出数组元素的数组索引
1 | /* |
-
每个作者的book的tag合集
1 | /* |
-
使用
preserveNullAndEmptyArrays选项在输出中包含缺少tag字段,null或空数组的文档
1 | # 初始化数据,加入一些tag为空数组或不存在tag的文档 |
1 | /* |
skip/$sort
-
$limit:限制传递到管道中下一阶段的文档数
-
$skip:跳过传递到管道中下一阶段的文档数
-
$sort:对传递到管道中下一阶段的文档进行排序
示例
-
姓名为xx006的作者的book的tag数组拆分为多个文档,按照收藏数降序排序,跳过2个文档,取5个文档
1 | /* |
-
标签的热度排行,标签的热度则按其关联book文档的收藏数(favCount)来计算
1 | /* |
$bucket
-
$bucket:根据指定的条件和边界,将文档分组到不同的桶中
示例
-
统计book文档收藏数[0,10),[10,60),[60,80),[80,100),[100,+∞)
1 | /* |
$lookup
-
$lookup:将文档中的一个字段的值与另一个集合中的文档进行匹配,然后将匹配的文档添加到当前文档中
-
语法
1 | db.collection.aggregate([{ |
| 名称 | 描述 |
|---|---|
from |
同一个数据库下等待被Join的集合。 |
localField |
源集合中的match值,如果输入的集合中,某文档没有 localField这个Key(Field),在处理的过程中,会默认为此文档含有 localField:null的键值对。 |
foreignField |
待Join的集合的match值,如果待Join的集合中,文档没有foreignField值,在处理的过程中,会默认为此文档含有 foreignField:null的键值对。 |
as |
为输出文档的新增值命名。如果输入的集合中已存在该值,则会覆盖掉。 |
-
其语法功能类似于下面的伪SQL语句
1 | SELECT *, <output array field> |
示例
-
准备数据
1 | # 顾客信息 |
-
查询顾客的订单信息,关联字段为customerCode顾客号码
1 | /* |
-
根据订单信息关联顾客信息和订单明细
1 | /* |