











Java并发编程--线程池之ThreadPoolExecutor
摘要
-
本文介绍线程池 ThreadPoolExecutor 相关技术
-
本文基于
jdk1.8
线程池介绍
-
线程池是一种用于管理和复用线程的机制,它可以有效地控制并发线程的数量,减少线程创建和销毁的开销,并提高应用程序的性能和资源利用率。
Java内置的线程池
-
FixedThreadPool(固定线程池):该线程池包含固定数量的线程,提交的任务会在这些线程中执行。如果所有线程都正在忙于执行任务,新任务将会在任务队列中等待。
1 | // nThreads是线程池中线程的数量,核心线程数和最大线程数一样 |
- 优点:具有固定数量的线程,可确保线程数始终保持在指定的数量上。适用于需要控制并发线程数的场景,可以避免线程数量过多导致系统资源耗尽。
- 缺点:任务队列无界限制,如果任务提交速度超过线程处理速度,可能导致队列积压过多任务,最终可能导致内存溢出。不适合处理大量长时间运行的任务。
-
CachedThreadPool(缓存线程池):该线程池不固定线程数量,可以根据需要自动创建新线程,也会自动回收闲置的线程。适用于执行大量短期的任务。
1 | ExecutorService executor = Executors.newCachedThreadPool(); |
- 优点:线程数量不固定,根据任务的提交情况动态创建和回收线程。适用于短期、异步的任务处理,能够灵活调配线程资源。
- 缺点:由于线程数量不受限制,如果任务提交速度过快,可能导致创建过多的线程,进而消耗过多的系统资源,甚至导致系统崩溃。
-
SingleThreadExecutor(单线程池):该线程池只包含一个线程,用于顺序执行任务。如果该线程因异常而终止,会创建一个新的线程来替代。
1 | ExecutorService executor = Executors.newSingleThreadExecutor(); |
- 优点:只有一个工作线程,保证任务按照指定顺序执行。适用于需要顺序执行任务的场景,例如需要按照任务的提交顺序进行处理。
- 缺点:由于只有一个线程,如果该线程因为异常而终止,线程池将会创建一个新线程代替,可能会带来额外的开销。不适合处理大量耗时的任务。
-
ScheduledThreadPool(调度线程池):该线程池用于定时或周期性执行任务。可以指定任务的延迟时间或执行周期。
1 | // corePoolSize是线程池中核心线程的数量 |
- 优点:用于定时或周期性执行任务,可以指定任务的延迟时间或执行周期。适用于需要定时执行任务的场景。
- 缺点:线程数量固定,如果任务过多或任务执行时间过长,可能会导致任务堆积,影响调度的准确性。
为什么不推荐使用这些内置线程池?
-
任务队列没有限制:内置线程池的任务队列默认是无界的,如果任务提交速度过快,可能会导致队列积压过多任务,最终导致内存溢出或系统资源耗尽。
-
默认的线程拒绝策略:内置线程池的默认线程拒绝策略是抛出RejectedExecutionException,当任务提交超过线程池的处理能力时,会导致任务被拒绝执行。这可能会导致任务丢失或需要手动处理拒绝的任务。
-
配置限制有限:内置线程池提供了一些参数来配置线程池的行为,例如核心线程数、最大线程数、任务队列等。然而,这些参数可能不足以满足复杂的业务需求。对于更复杂的场景,可能需要更高级的线程池实现或手动创建自定义线程池。
-
缺乏监控和扩展功能:内置线程池的功能相对简单,缺乏对线程池的监控和扩展能力。在一些需要对线程池进行监控、统计或动态调整的场景下,内置线程池可能无法满足需求。
-
鉴于上述原因,对于复杂的应用程序和具有特定需求的场景,建议使用更高级的线程池实现,例如ThreadPoolExecutor类,它提供了更多的配置选项和灵活性,以满足各种需求。此外,还可以考虑使用第三方的线程池库,如Guava或Apache Commons等,它们提供了更多功能和扩展性。自定义线程池能够更好地适应特定的业务需求,并提供更好的控制和可扩展性。
ThreadPoolExecutor介绍
-
ThreadPoolExecutor是Java中的一个灵活且强大的线程池实现,它提供了很多配置选项,你可以将任务提交给线程池执行,并根据需要动态调整线程池的大小和配置。它是并发编程中常用的工具,适用于各种需要处理异步任务的场景,如服务器端应用程序、多线程数据处理和并行计算等。
-
ThreadPoolExecutor的一些关键特点:
- 1.线程池大小控制:你可以通过设置核心线程池大小(corePoolSize)和最大线程池大小(maximumPoolSize)来控制线程池中的线程数量。核心线程池大小是线程池中一直保持活动的线程数,而最大线程池大小是线程池中允许存在的最大线程数。
- 2.任务排队:ThreadPoolExecutor提供了多种任务排队策略,例如无界队列(Unbounded Queue)、有界队列(Bounded Queue)和同步移交(Synchronous Transfer)。你可以根据需要选择适合的任务排队策略,以控制任务的提交和执行。
- 3.线程生命周期管理:ThreadPoolExecutor负责管理线程的生命周期,包括线程的创建、执行任务和销毁。它会根据线程池的配置自动创建和回收线程,以及处理线程的异常和空闲状态。
- 4.拒绝策略:当线程池无法接受新的任务时,ThreadPoolExecutor提供了多种拒绝策略来处理这种情况。例如,你可以选择丢弃任务、抛出异常或在调用者线程中执行任务。
- 5.统计和监控:ThreadPoolExecutor提供了一些方法来获取线程池的状态和统计信息,比如活动线程数、已完成任务数、任务队列大小等。这些信息可以帮助你监控和调优线程池的性能。
ThreadPoolExecutor类的一些常用API
| 方法签名 | 描述 |
|---|---|
void execute(Runnable command) |
提交一个Runnable任务给线程池执行 |
Future<?> submit(Runnable task) |
提交一个Runnable任务给线程池执行,并返回一个表示任务结果的Future对象 |
Future<T> submit(Callable<T> task) |
提交一个Callable任务给线程池执行,并返回一个表示任务结果的Future对象 |
void shutdown() |
顺序关闭线程池,不再接受新的任务 |
List<Runnable> shutdownNow() |
立即关闭线程池,并尝试终止所有正在执行的任务,返回的是尚未开始处理的任务列表,以及已经开始但尚未完成的任务列表。 |
boolean isShutdown() |
判断线程池是否已经关闭 |
boolean isTerminated() |
判断线程池是否已经终止,已经终止返回true |
boolean awaitTermination(long timeout, TimeUnit unit) |
等待线程池终止,最多等待指定的时间 ,超时后仍未终止返回false |
void setCorePoolSize(int corePoolSize) |
设置核心线程池大小 |
int getCorePoolSize() |
获取核心线程池大小 |
void setMaximumPoolSize(int maximumPoolSize) |
设置最大线程池大小 |
int getMaximumPoolSize() |
获取最大线程池大小 |
void setKeepAliveTime(long time, TimeUnit unit) |
设置非核心线程的空闲时间 |
long getKeepAliveTime(TimeUnit unit) |
获取非核心线程的空闲时间 |
BlockingQueue<Runnable> getQueue() |
获取任务队列 |
void setRejectedExecutionHandler(RejectedExecutionHandler handler) |
设置拒绝策略 |
RejectedExecutionHandler getRejectedExecutionHandler() |
获取拒绝策略 |
int getActiveCount() |
获取活动线程数 |
long getCompletedTaskCount() |
获取已完成的任务数 |
long getTaskCount() |
获取总任务数 |
ThreadPoolExecutor的创建与配置
1 | int corePoolSize = 5; // 核心线程池大小 |
ThreadPoolExecutor的调用
没有返回值
1 | // 通过调用execute()方法,将任务提交给ThreadPoolExecutor执行,这里的MyTask是实现了Runnable接口的自定义任务类。 |
有返回值
1 | // 通过调用submit()方法,将任务提交给ThreadPoolExecutor执行,并返回了一个Future对象,用于获取任务的执行结果。 |
-
需要注意的是,submit()方法可以接受不同类型的任务(Runnable或Callable),并返回一个Future对象。对于Runnable类型的任务,submit()方法返回的Future对象的get()方法将始终返回null。
执行流程图
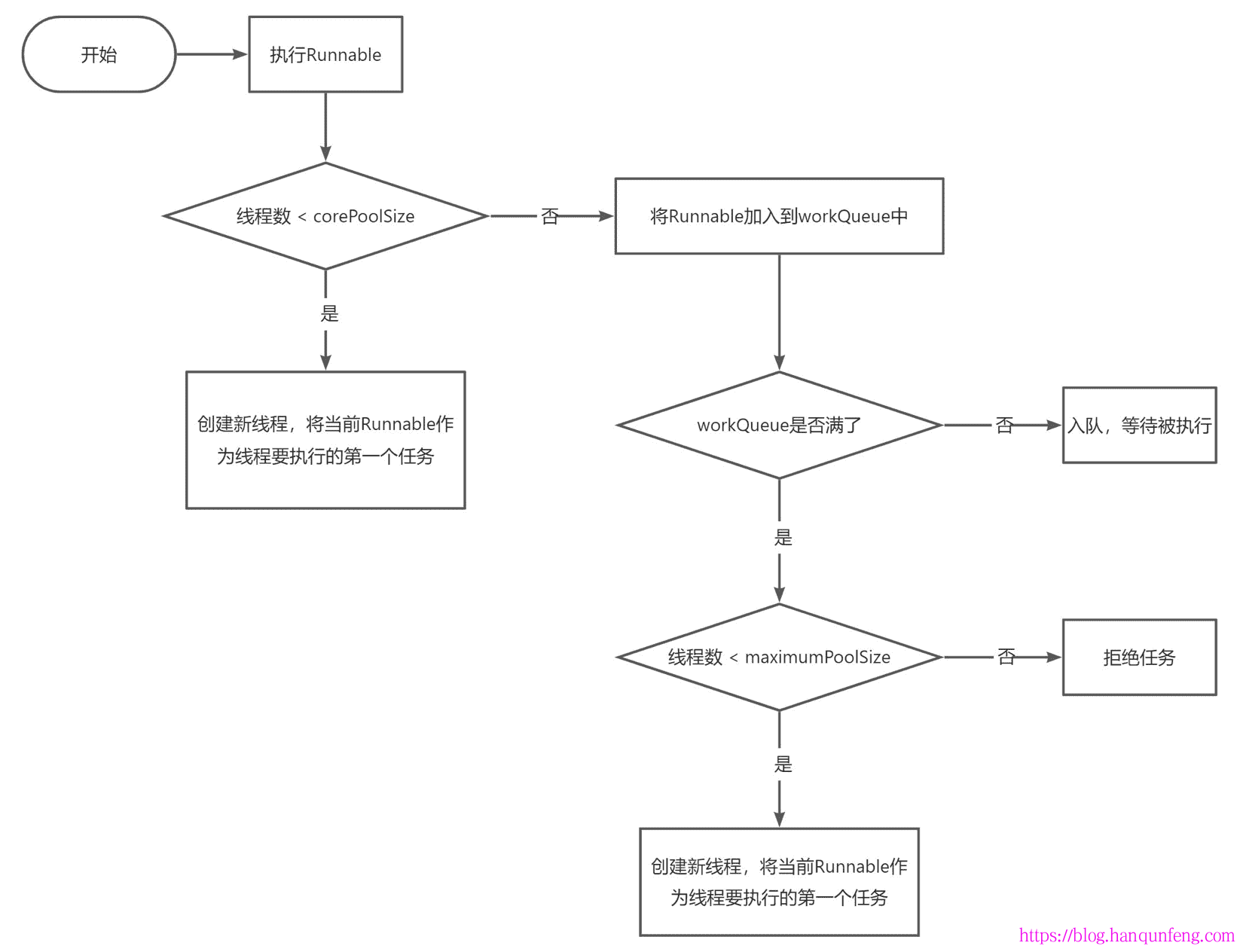
-
提交一个Runnable时,不管当前线程池中的线程是否空闲,只要数量小于核心线程数就会创建新线程。
-
ThreadPoolExecutor是非公平的,比如队列满了之后提交的Runnable可能会比正在排队的Runnable先执行。
ThreadPoolExecutor的关闭
1 | // 不再接受新的任务,但是正在处理的任务和队列中尚未处理的任务会继续执行完毕 |
-
调用
shutdownNow()也并不意味着线程池立刻就关闭了,可以通过如下方式判断线程池是否已经终止
| 方法签名 | 描述 |
|---|---|
boolean isTerminated() |
判断线程池是否已经终止,已经终止返回true |
boolean awaitTermination(long timeout, TimeUnit unit) |
等待线程池终止,最多等待指定的时间 ,超时后仍未终止返回false |
ThreadPoolExecutor线程池的五种状态
-
RUNNING:会接收新任务并且会处理队列中的任务
-
SHUTDOWN:不会接收新任务并且会处理队列中的任务
-
STOP:不会接收新任务并且不会处理队列中的任务,并且会中断在处理的任务
-
TIDYING:所有任务都终止了,线程池中也没有线程了,这样线程池的状态就会转为TIDYING,一旦达到此状态,就会调用线程池的terminated()
-
TERMINATED:terminated()执行完之后就会转变为TERMINATED
这五种状态并不能任意转换,只会有以下几种转换情况:
-
RUNNING->SHUTDOWN:手动调用shutdown()触发,或者线程池对象GC时会调用finalize()从而调用shutdown() -
(RUNNING or SHUTDOWN)->STOP:调用shutdownNow()触发,如果先调shutdown()紧着调shutdownNow(),就会发生SHUTDOWN->STOP -
SHUTDOWN->TIDYING:队列为空并且线程池中没有线程时自动转换 -
STOP->TIDYING:线程池中没有线程时自动转换(队列中可能还有任务,但是永远不会被执行) -
TIDYING->TERMINATED:terminated()执行完后就会自动转换
线程池为什么一定得是阻塞队列?
线程池中的线程在运行过程中,执行完创建线程时绑定的第一个任务后,就会不断的从队列中获取任务并执行,那么如果队列中没有任务了,线程为了不自然消亡,就会阻塞在获取队列任务时,等着队列中有任务过来就会拿到任务从而去执行任务。通过这种方法能最终确保,线程池中能保留指定个数的核心线程数。
线程发生异常,会被移出线程池吗?
-
会。但为了保证维持住固定的核心线程数,会再创建一个新的线程。
-
单个任务的异常情况,不会直接影响线程池中的其他线程,线程池会继续执行其他任务,除非遇到无法处理的异常,例如线程池被关闭或发生了无法恢复的错误。
-
然而,如果某个任务的异常没有被正确处理,可能会导致整个线程池无法正常工作。例如,如果异常被忽略或没有适当的错误日志记录,可能会导致问题的隐患积累或任务无法正确完成。
-
因此,在使用线程池时,建议为任务提供适当的异常处理逻辑,以确保及时捕获和处理异常,以及记录错误信息。这有助于提高线程池的可靠性和稳定性。
-
也可以为线程池配置全局异常处理逻辑,如果线程执行过程中发生了未捕获的异常,可以通过下面的方式处理异常:
1 | ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 500, 30, TimeUnit.SECONDS, new ArrayBlockingQueue<>(200)); |
线程池的核心线程数、最大线程数该如何设置?
-
线程池中的核心线程数计算方法:
名词解释
CPU核心数[逻辑核] = Runtime.getRuntime().availableProcessors();
线程等待时间[阻塞时间]:指的就是线程没有使用CPU的时间,比如阻塞在了IO
线程运行总时间:指的是线程执行完某个任务的总时间
阻塞系数 = 线程等待时间[阻塞时间] / 线程运行总时间
PS: 可以在压测时使用JVM提供的jvisualvm得到对应线程运行的总时间和总时间(CPU),通过计算得到:
线程等待时间 = 总时间 - 总时间(CPU)
线程运行总时间 = 总时间
-
1.计算密集型:内存运算,尽可能避免发生线程上下文切换
核心线程数 = CPU核心数 + 1 -
2.IO密集型:一般文件读写、数据库读写、网络接口调用等都属于IO密集型
方法1:
- 核心线程数 = CPU核心数 * (1 + 阻塞系数)
- 该方法下,通常设置为 CPU核心数 * 2,所以: 4C服务器,线程数为8个左右方法2 [推荐]:
- 核心线程数 = CPU核心数 / (1 - 阻塞系数)
- 该方法下,经验上一般阻塞系数取值为0.8~0.9,所以: 4C服务器,线程数为20 ~ 40个为宜
PS: 经验上来讲,方法2更为准确,但以上只是理论,实际工作中情况会更复杂,比如一个应用中,可能有多个线程池,除开线程池中的线程可能还有很多其他线程,或者除开这个应用还是一些其他应用也在运行,所以实际工作中如果要确定准确的线程数,最好是压测。
总结
-
CPU密集型任务:CPU核心数+1,这样既能充分利用CPU,也不至于有太多的上下文切换成本
-
IO密集型任务:建议压测,或者先用公式计算出一个理论值(理论值通常都比较小)
-
对于核心业务(访问频率高),可以把核心线程数设置为我们压测出来的结果,最大线程数可以等于核心线程数,或者大一点点,比如我们压测时可能会发现500个线程最佳,但是600个线程时也还行,此时600就可以为最大线程数
-
对于非核心业务(访问频率不高),核心线程数可以比较小,避免操作系统去维护不必要的线程,最大线程数可以设置为我们计算或压测出来的结果。
小贴士
Tomcat中的线程池ThreadPoolExecutor
- Tomcat中有一个与JUC包下同名的
ThreadPoolExecutor,即org.apache.tomcat.util.threads.ThreadPoolExecutor,它扩展了Java标准库中的java.util.concurrent.ThreadPoolExecutor,具有一些特定的功能和行为:- 入队时,如果线程池的线程个数等于最大线程池数才入队,如果线程池的线程个数小于最大线程池数,会返回false,表示入队失败
- 提交任务时,会先判断线程个数是否小于核心线程数,如果小于则创建线程,如果等于核心线程数,会入队,但是线程个数小于最大线程数会入队失败,从而会去创建线程
- 随着任务的提交,会优先创建线程,直到线程个数等于最大线程数才会入队
- 另外,提交任务时,如果正在处理的任务数小于线程池中的线程个数,那么也会直接入队,而不会去创建线程