









Kafka 的安装:基于 Zookeeper
摘要
-
本文介绍 CentOS9 中 Kafka 的安装与使用,基于 Zookeeper。
-
本文使用的 Kafka 版本为 3.9.1。Kafka 团队宣布 3.9 会是 最后一个还带有被弃用的 ZooKeeper 模式 的主要版本。以后版本(如 4.0)将完全弃用 ZooKeeper。
Kafka 简介
-
Apache Kafka 是一个
分布式的流处理/事件流平台,既可以作为消息系统,也可以作为持久化的日志/记录存储与流处理平台。 -
它的设计目标是高吞吐、低延迟、可水平扩展、容错,以及可持久化数据。
-
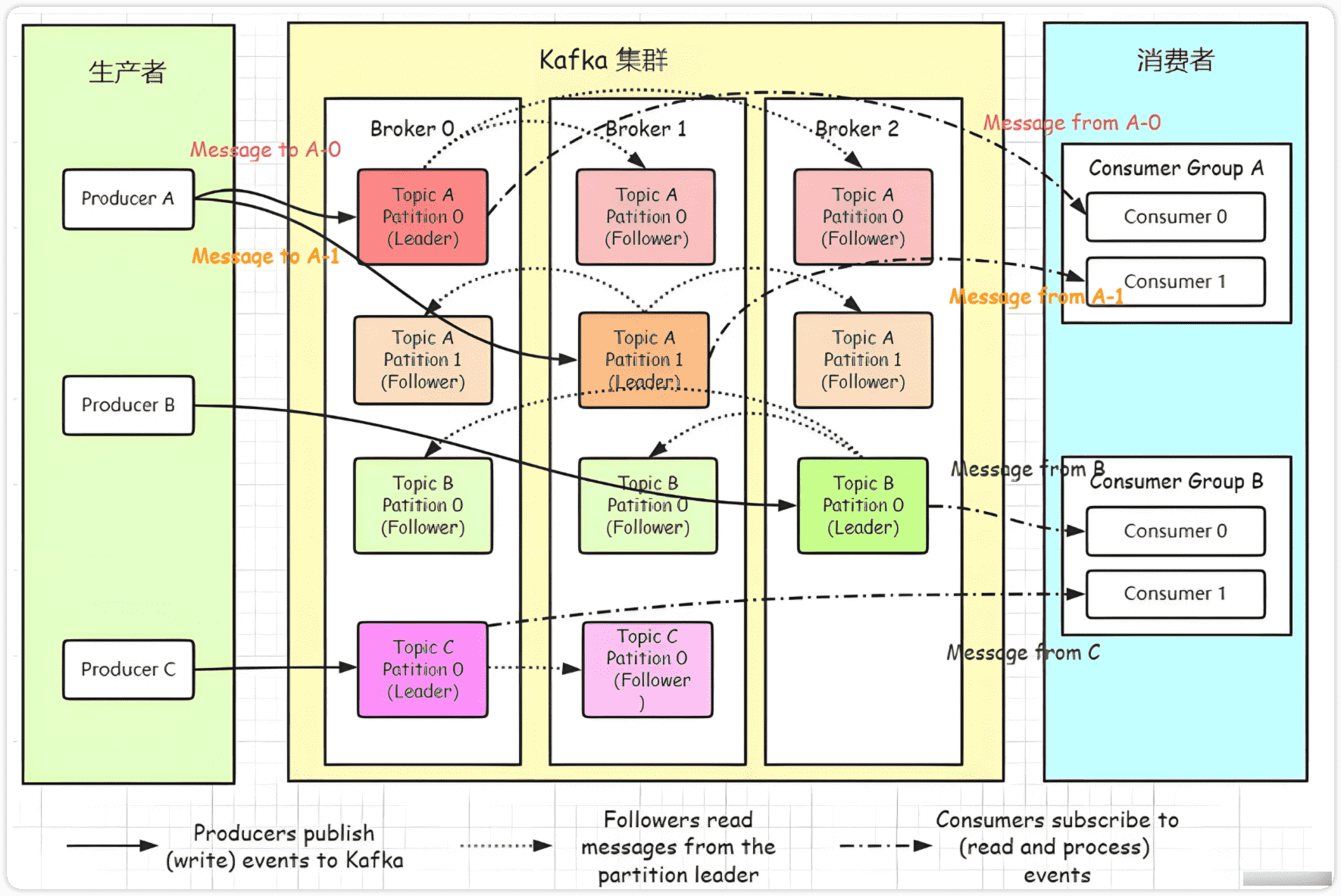
在 Kafka 中,消息被归类为
主题(Topic),每个主题可以根据配置被拆分为多个分区(Partition),每个分区内部消息是严格有序的,并以追加方式写入。消费者可以按偏移量(offset)读取消息。 -
Kafka 提供多个 API:Producer、Consumer、Streams(流处理)、Connect(与外部系统整合)等。
-
Kafka 的核心架构要素与工作机制
| 组件 / 概念 | 作用 / 描述 |
|---|---|
| Broker(节点 / 服务器) | Kafka 集群中的服务器实例,负责接收、存储、分发消息 |
| Topic | 消息的“分类”逻辑单元,Producer 写入、Consumer 读取 |
| Partition | 一个 Topic 被划分的子单元。分区使得主题可以横向扩展,并支持并行读写 |
| Offset | 每条消息在某个分区中的唯一位置标识,消费者根据 offset 来决定下一条读取 |
| Replication(副本) | 为了容错性,每个分区可以有多个副本(副本分布在不同 Broker 上) |
| Leader / Follower | 在副本中,一个副本为 Leader,接受读写请求;其他为 Follower,从 Leader 同步数据 |
| Consumer Group | 一组消费者共同消费一个 Topic。每个分区在同一个消费者组中通常只被一个消费者 “拥有” |
| ZooKeeper / KRaft | 用于元数据管理、集群协调(在较老版本中是 ZooKeeper;新版本推向 KRaft) |
-
消息写入流程(简化):
- Producer 将消息发送给某个 Topic 的 Leader 分区节点
- Leader 接收到消息后,将其追加写入本地日志,并返回确认(ACK)
- Follower 副本从 Leader 拉取数据进行同步
- 消费者根据自己的 offset 从对应 Partition 中读取消息
-
消费控制与容错:
- 消费者维护自己的 offset(可以自动提交,也可手动控制),这样即使消费者重启,也可以从上次停止的位置继续。
- 如果某个 Broker 宕机,副本可以切换(Leader 选举),保证服务继续。
- 分区与副本机制使得 Kafka 能够扩展容量 & 提高可靠性。
-
Kafka 的典型使用场景
| 场景类别 | 说明 |
|---|---|
| 实时数据管道 / 数据集成 | 用于将各种数据源(如日志、数据库变更、传感器、用户事件等)实时采集、传输、分发到下游系统(如 OLAP、搜索引擎、监控平台等),构建高效的数据通道。 |
| 事件驱动 / 事件溯源 | 记录系统内部或跨系统的事件(状态变化),实现事件驱动架构(EDA)或事件溯源(Event Sourcing),可用于审计、回放、状态重建等。 |
| 日志聚合 / 分析 | 将分布式系统中的应用日志、监控指标、操作日志等统一收集到 Kafka 中,集中存储与分析,常与 ELK、ClickHouse 等结合。 |
| 流处理 | 与 Kafka Streams、Apache Flink、Spark Streaming 等流处理框架配合,对流经 Kafka 的数据进行实时计算、聚合、过滤、窗口统计等操作。 |
| 系统解耦 / 异步通信 | 作为系统间的消息中间件,实现发布-订阅模式,减少系统间耦合,支持异步通信、流量削峰、缓冲等,提升系统稳定性与扩展性。 |
Kafka 安装
-
这里先介绍基于 Zookeeper 的安装方式,下文会介绍基于 KRaft 的安装方式。
-
Kafka 3.9.1 的安装与运行需要 JDK 8+,所有我们需要提前安装 JDK 8+。可以选择OpenJDK,清华大学镜像站
1 | # root 用户 |
-
安装过程参考官网文档Kafka Quick Start。
单机安装
-
部署kafka都会使用集群模式,单机模式只作为学习试用。
-
下载Kafka,下载页面
1 | # root 用户 |
-
启动 Zookeeper,kafka内置了zookeeper,所以不需要单独安装。
1 | zookeeper-server-start.sh /usr/local/kafka/kafka3/config/zookeeper.properties |
-
启动 kafka,需打开另一个终端
1 | # -daemon 后台运行 |
小贴士
- 注意:默认情况下 启动 kafka 需要的内存大小为 1G,这一点可以在 kafka-server-start.sh 脚本中查看到
1 | if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then |
- 所以如果内存不够,可以设置环境变量后再启动kafka
1 | export KAFKA_HEAP_OPTS="-Xmx512M -Xms512M" |
-
测试
1 | # 创建 topic |
集群安装
-
集群安装需要准备多个节点,这里我准备三个节点,分别如下:
1 | 10.250.0.7 |
搭建 Zookeeper 集群
-
关于如何搭建 Zookeeper 集群,可以参考我之前的文章 Zookeeper 的安装及使用
-
如果图省事也可以直接使用 Kafka 自带的 zookeeper,编辑其配置文件
config/zookeeper.properties如下,注意要在dataDir目录下创建myid文件
1 | dataDir=/usr/local/kafka/dataDir/zookeeper |
配置 Kafka 集群
-
修改主机的主机名
1 | hostnamectl hostname worker1 |
-
为了后续方便维护,将ip地址映射到 hosts 文件中
1 | 10.250.0.7 worker1 |
-
编辑
config/server.properties文件,需要修改如下配置项
1 | #broker 的全局唯⼀编号,不能重复,只能是数字。 |
-
分别在三个节点上启动 Kafka
1 | kafka-server-start.sh -daemon /usr/local/kafka/kafka3/config/server.properties |
-
测试
1 | # 创建 topic |
-
总体信息(Topic 概览)
1 | Topic: disTopic TopicId: VUK7Mc9oQdS1mjGG7OhQzQ PartitionCount: 3 ReplicationFactor: Configs: |
| 字段 | 含义 |
|---|---|
| Topic: disTopic | Topic 名称,即当前描述的主题。 |
| TopicId: VUK7Mc9oQdS1mjGG7OhQzQ | Kafka 内部自动生成的唯一标识符(UUID),Kafka 3.x 之后引入,用于区分同名但不同生命周期的 topic。 |
| PartitionCount: 3 | 该主题有 3 个分区(partition)。每个分区存储一部分消息。 |
| ReplicationFactor: | 副本因子。这里虽然输出中没显示具体值,但可从每行分区配置推断是 3(每个分区有 3 个副本)。 |
| Configs: | topic 的配置项(例如清理策略、压缩类型等),如果为空,说明使用默认配置。 |
-
分区详情(每个 Partition 一行)
1 | Topic: disTopic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Elr: N/A LastKnownElr: N/A |
| 字段 | 含义 |
|---|---|
| Partition: 0 | 第 0 号分区。 |
| Leader: 2 | 该分区当前的 Leader Broker 是 broker ID = 2,只有 Leader 才处理读写请求。 |
| Replicas: 2,3,1 | 该分区的所有副本存放在哪些 Broker 上(即副本分布),分别是 broker 2、3、1。 |
| Isr (In-Sync Replicas): 2,3,1 | 当前与 Leader 保持同步的副本集合。这里所有副本都在同步中(健康状态 👍)。 |
| Elr / LastKnownElr | Kafka 新版本中引入的 “Enhanced Leader Replica” 状态,目前未启用(N/A)。 |
Kafka 命令
-
管理 topic
1 | # 创建 topic |