











RabbitMQ 之 Cluster
摘要
-
本文介绍 RabbitMQ 的 Cluster 的基本概念和用法。
-
本文使用的 RabbitMQ 版本为 4.1.4。
RabbitMQ Cluster(集群) 简介
-
在 RabbitMQ 中,Cluster(集群) 是多个节点组成的集合,用于实现高可用和负载均衡。
-
RabbitMQ 集群是一个或多个(三个、五个、七个或更多)节点的逻辑分组, 每个节点共享 用户、虚拟主机、队列、流、交换、绑定、运行时参数和其他分布式状态。
-
在 RabbitMQ 中,Cluster(集群)的节点分为两种:
- 磁盘节点(disk):会把集群的所有元数据信息(比如交换机、绑定、队列、虚拟主机等信息)持久化到磁盘中。Master 节点必须是磁盘节点。
- 内存节点(ram):只会将这些信息保存到内存中,如果该节点宕机或重启,内存节点的数据会全部丢失,而磁盘节点的数据不会丢失。Slave 节点可以是内存节点。
-
RabbitMQ 4.0 开始, 集群不再区分
普通集群模式(Classic Cluster)与镜像集群模式(Mirrored Queue Cluster),集群创建好后,会根据队列的初始复制因子参数决定为该队列创建多少个副本,比如Quroum Queue的参数是x-quorum-initial-group-size,默认为3。 -
RabbitMQ 4.0 开始,
Quroum Queue和Stream Queue默认开启节点间消息复制,但是Classic Queue队列不支持节点间的消息复制;
RabbitMQ 4.0以前的 集群分为两种模式
-
- 普通集群模式(Classic Cluster)
- 在 普通集群模式下,RabbitMQ 节点通过 Erlang 分布式系统实现互联,集群内的各个节点共享 消息队列、交换机、绑定等元素。
- 普通集群的特点:
- 共享队列:队列数据仅存储在单一节点上,只有该节点可以处理队列中的消息。
- 不自动复制数据:在普通集群中,消息并不会自动复制到其他节点。如果某个节点挂掉,队列上的消息就会丢失,无法恢复。
- 负载均衡:交换机(Exchange)会把消息发送到不同的队列,但队列数据仍然只在一个节点上。因此,普通集群适合不要求极高可用性的场景。
- 不具备高可用性:由于数据不会在集群的其他节点中复制,普通集群在某个节点宕机时,可能会导致消息丢失和系统不可用。
-
- 镜像集群模式(Mirrored Queue Cluster)
- 镜像集群模式 是为了 高可用性 设计的,在该模式下,队列的数据会在集群中的多个节点上进行 复制(镜像),从而保证即使某个节点出现故障,数据也不会丢失。
- 镜像集群的特点:
- 队列镜像:在镜像集群模式中,队列数据会在集群中的多个节点上复制。每个队列都有一个主节点和多个镜像节点。
- 高可用性:消息会被复制到集群的其他节点上,从而保证如果一个节点宕机,数据不会丢失,系统能迅速恢复。
- 节点故障恢复:当一个节点挂掉时,其他节点会继续处理该队列的消息,保证业务的高可用性。
- 网络负担较重:由于需要在多个节点之间进行数据同步和复制,所以镜像队列模式会增加集群的网络负担和磁盘 I/O。
- 性能影响:镜像队列模式会稍微影响性能,因为每次消息处理后,都需要将数据同步到其他镜像节点,增加了延迟。
集群搭建
-
准备三台服务器,分别安装 RabbitMQ ,安装方法参看 RabbitMQ 的安装及使用
-
开放端口
| 端口范围 | 用途 | 备注 |
|---|---|---|
| 4369 | epmd(Erlang Port Mapper Daemon) | RabbitMQ 节点和 CLI 工具使用的帮助程序发现守护进程。 |
| 6000-6500 | RabbitMQ Stream 复制使用 | 用于 RabbitMQ Stream 的数据复制。 |
| 25672 | Erlang 分发服务器端口 | 用于节点间和 CLI 工具通信,默认情况下仅限于单个端口(AMQP端口 + 20000)。 |
| 35672-35682 | Erlang 分发客户端端口 | 用于 CLI 工具与节点通信,计算为服务器分发端口 + 10000 到 服务器分发端口 + 10010。 |
-
分别修改三台服务器的
hostname
1 | hostnamectl hostname rabbitmq01 |
-
分别修改三台服务器的
/etc/hosts文件
1 | 10.250.0.56 rabbitmq01 |
-
同步集群节点中的cookie
- 默认会在
/var/lib/rabbitmq/目录下生成一个.erlang.cookie,里面有一个字符串。 - 我们使用
rabbitmq01节点作为集群的主节点,其他节点作为集群的成员节点,我们要做的就是保证集群中三个节点的这个cookie字符串一致。 - 将
rabbitmq01的/var/lib/rabbitmq/.erlang.cookie文件中的cookie字符串复制到其他节点的/var/lib/rabbitmq/.erlang.cookie文件中。
- 默认会在
-
分别启动三台服务器的 RabbitMQ 服务
1 | systemctl start rabbitmq-server |
-
分别登录
rabbitmq02和rabbitmq03节点,执行如下命令,将节点加入集群
1 | # 停掉rabbitmq应用 |
-
登录 任意 节点,执行如下命令,查看集群状态
1 | rabbitmqctl cluster_status |
PS: 由于ram节点减少了很多与硬盘的交互,所以,ram节点的元数据使用性能会比较高。但是,同时,这也意味着元数据的安全性是不如disk节点的。在我们这个集群中, rabbitmq02 和 rabbitmq03 都以 ram节点 的身份加入到 rabbitmq01 集群里,因此,是存在单点故障的。如果 rabbitmq01 节点服务崩溃,那么元数据就有可能丢失。在企业进行部署时,性能与安全性需要自己进行平衡。
-
登录任意节点的管理页面,查看集群状态
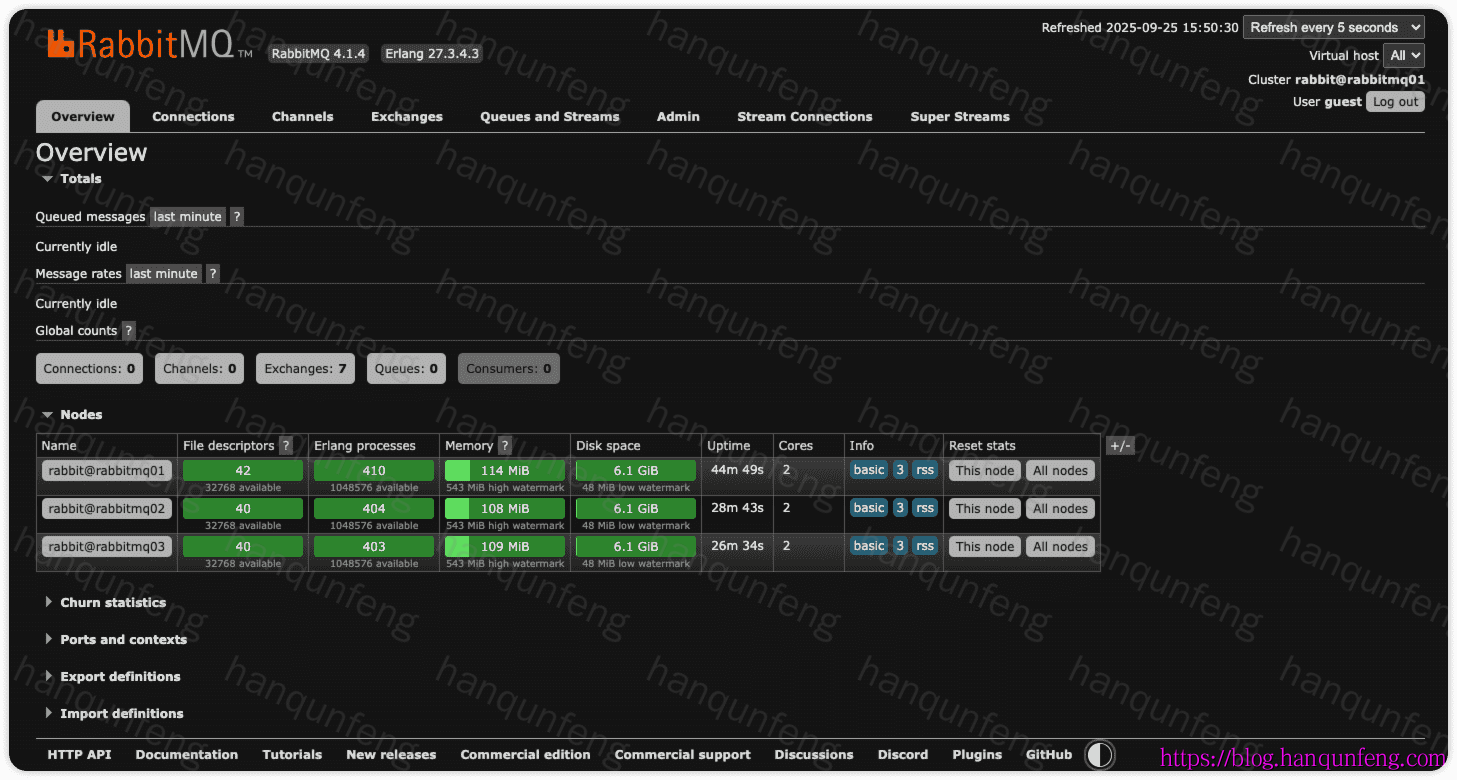
-
此时我们在任意节点中创建虚拟主机、队列、交换机和绑定关系 等元数据,都会自动同步到其他节点中。
-
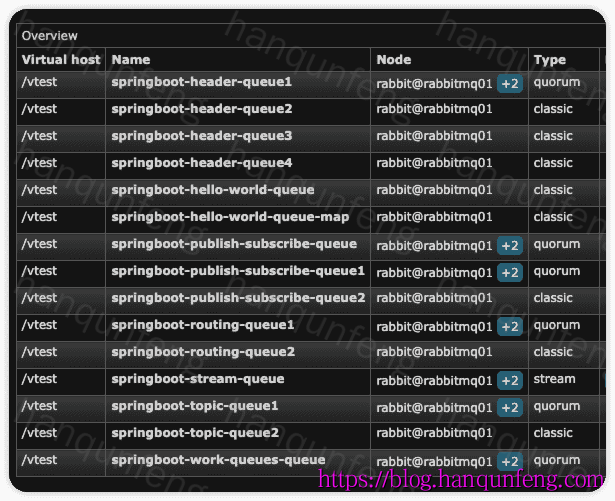
我们也可以在 管理控制台 中查看队列时看到,此时多个一列,
Node列,显示该队列在哪些节点中存在。只有Quorum 队列和Stream 队列才会显示多个节点,因为Classic 队列不支持多节点复制。
-
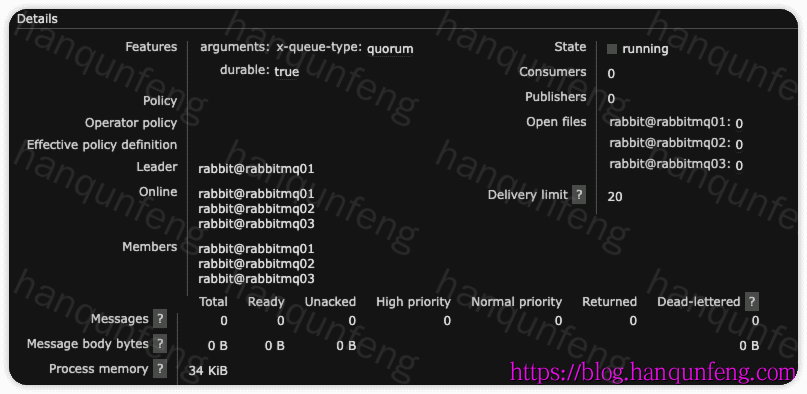
查看某个具体的
Quorum 队列或Stream 队列,可以看到更详细的说明
-
此时新建队列,会要求我们指定主节点(Leader),即负责存储消息的的节点,而
Quorum 队列或Stream 队列,会自动将消息复制到其它节点(Members)。- Leader: 队列的主节点,负责存储消息。
- Members: 队列的成员节点,负责存储消息的副本。
演示队列复制
-
默认情况下,
Quorum 队列和Stream 队列的 复制数 都为 3,这里为了演示,我在增加一个节点rabbitmq04,请自行按上面的方法添加。
Quorum 队列
-
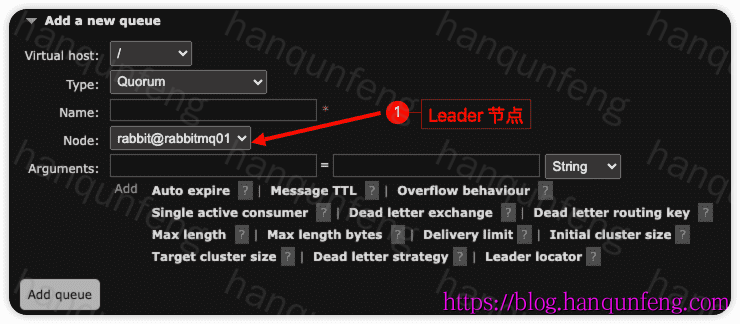
在页面上创建一个
Quorum 队列,与单节点上创建队列的区别就是需要我们选择主节点。
-
通过 客户端 创建队列时,默认情况下,连接哪个节点,哪个节点就是Leader,但也可以通过参数
x-queue-leader-locator指定主节点的选择策略。
1 | rabbitmqadmin queues declare --vhost "/vtest" --name "target.quorum.queue.name" --type "quorum" --durable true --arguments '{"x-queue-leader-locator":"balanced"}' |
-
创建成功后,可以看到
Quorum 队列的主节点和成员节点,可以看到这里成员节点有三个,除了主节点外,其余节点由集群自动选择。

-
也就是说,默认情况下,
Quorum 队列的复制数是3,如果我们希望改变复制数,可以在创建队列时指定参数x-quorum-initial-group-size,其值为大于 0 的整数,若设置值大于实际成员节点数,则以实际成员节点数为准。x-quorum-initial-group-size设置为1时便不进行复制了。 -
如果集群中增加了新的节点,希望队列也被复制到新的节点中,可以通过如下命令,将新的节点加入成员节点中:
1 | # rabbitmq-queues add_member [-p <vhost>] <queue-name> <node> |
-
如果希望将节点从成员节点中移除,可以通过如下命令:
1 | # rabbitmq-queues delete_member [-p <vhost>] <queue-name> <node> |
-
另外,当通过
forget_cluster_node命令从集群中永久删除节点时,会自动将队列关联的节点从成员节点中移除。 -
删除节点时,请使用如下命令:
1 | # 因为要删除 rabbitmq04 节点,所以以下命令不能在 rabbitmq04 节点执行 |
-
新增节点后,一个个的对原有的队列进行复制扩展非常麻烦,可以通过如下命令快速对符合条件的队列进行复制扩展:
1 | # rabbitmq-queues grow <node> <all | even> [--vhost-pattern <pattern>] [--queue-pattern <pattern>] |
Stream 队列
-
Stream 队列 与 Quorum 队列 类似,通过哪个节点创建队列,哪个节点就是 Leader,但也是可以通过参数
x-queue-leader-locator指定主节点的选择策略。 -
创建 Stream 队列时,默认复制数就是当前集群的节点数(Quorum 队列 默认是 3),可以通过指定参数
x-initial-cluster-size进行初始设置。 -
添加新的节点时,与 Quorum 队列 类似,Stream 队列 也不会自动进行复制,可以通过如下命令手动复制
1 | # rabbitmq-streams add_replica [-p <vhost>] <stream-name> <node> |
-
删除成员节点时,请使用如下命令:
1 | # rabbitmq-streams delete_replica [-p <vhost>] <stream-name> <node> |
-
查看节点复制状态
1 | # rabbitmq-streams stream_status [-p <vhost>] <stream-name> |
-
当流出现异常状态(如副本分布异常、领导节点挂掉)时,为了恢复可用性,可以重启流
1 | # rabbitmq-streams restart_stream [-p <vhost>] <stream-name> |