











RabbitMQ 之 Queue
摘要
-
本文介绍 RabbitMQ 的 Queue 的基本概念和用法。
-
本文使用的 RabbitMQ 版本为 4.1.4。
Queue(队列) 是什么?
-
在 RabbitMQ 中,队列(Queue) 是一种用于存储消息的 数据结构,消息会一直保存在队列中,直到被应用程序或服务消费为止。
-
生产者(Publisher) 把消息放进队列,消费者(Consumer) 从队列中取出消息。队列中的消息会按照 FIFO(先进先出)的顺序进行消费。
-
队列在生产者和消费者之间起到缓冲区的作用。生产者不需要知道消费者的存在,它们只需把消息发送到队列。消费者可以根据自身处理速度,按需消费消息。
-
RabbitMQ 目前 支持三种队列类型:
| 队列类型 | 描述 | 特点 | 典型用途 |
|---|---|---|---|
| Classic Queue(经典队列) | 最常用的队列类型,消息按 FIFO(先进先出)顺序存储和消费 | 支持持久化、优先级、TTL、死信等 | 大多数常规消息场景 |
| Quorum Queue(仲裁队列) | 基于 Raft 协议的队列,确保高可用和数据一致性 | 内置复制(副本数量可配置)、适合高可靠性场景,但吞吐量略低于经典队列 | 关键任务消息、高可靠性场景 |
| Stream Queue(流式队列) | 面向大量消息的高吞吐队列,支持消息按偏移量读取 | 类似 Kafka,可随机访问历史消息、顺序读取、可持久化大量消息 | 大数据流、日志处理、事件溯源 |
Classic Queue(经典队列)
-
RabbitMQ 经典队列(原始队列类型)是一种通用队列类型。实际上它是在 3.8.x 版本之前唯一的队列类型。
-
经典队列适用于数据安全不是优先事项的用例,因为存储在经典队列中的数据不会被复制。 经典队列使用非复制的 FIFO 队列实现。
-
经典队列不适合积累太多的消息,如果队列中积累的消息太多了,会严重影响客户端生产消息以及消费消息的性能。因此,经典队列主要用在数据量比较小,并且生产消息和消费消息的速度比较稳定的业务场景。比如内部系统之间的服务调用。
-
RabbitMQ 4.0 删除了对经典队列
version1的支持,同时也不再支持将 经典队列 的消息在节点间复制。
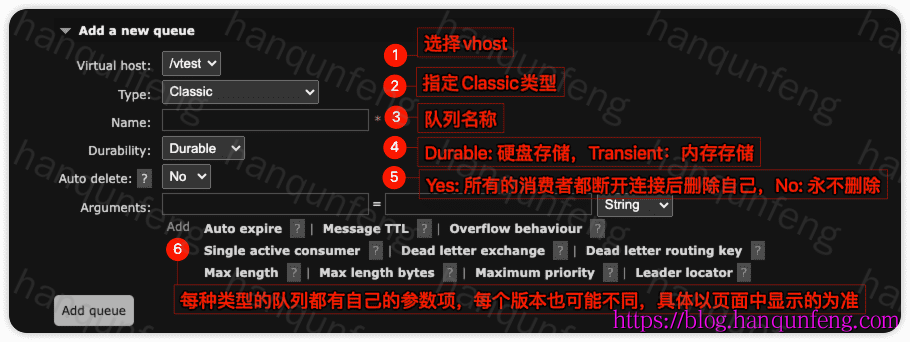
-
参数说明(每个版本可能都有变化,具体以页面显示为准)
| 参数名称 | 配置参数名 | 数据类型 | 作用说明 | 备注 / 使用场景 |
|---|---|---|---|---|
| Auto expire | x-expires |
整数(毫秒) | 队列在 指定时间内无人使用(无消费者、无发布、无访问) 时自动删除 | 类似“队列空闲过期时间”,节省资源 |
| Message TTL | x-message-ttl |
整数(毫秒) | 消息的 存活时间,超过时间后消息会被丢弃或发送到死信队列 | 用于限制消息时效性,如延迟消息或短期缓存 |
| Overflow behaviour | x-overflow |
字符串(drop-head 或 reject-publish) |
当队列达到 最大长度 或 最大字节数 时的行为 | - drop-head:丢弃最早的消息 - reject-publish:拒绝新的消息 |
| Single active consumer | x-single-active-consumer |
布尔值(true/false) | 是否启用 单活消费者模式,一次只允许一个消费者消费队列 | 用于严格顺序消费,保证某个消息不会被多个消费者同时处理 |
| Dead letter exchange (DLX) | x-dead-letter-exchange |
字符串 | 指定队列的 死信交换机,用于接收无法消费或过期的消息 | 常用于失败重试、消息补偿场景 |
| Dead letter routing key | x-dead-letter-routing-key |
字符串 | 消息转发到 DLX 时的 路由键 | 可以灵活转发到不同队列 |
| Max length | x-max-length |
整数 | 队列中 最大消息条数 | 超过时按照 Overflow behaviour 处理 |
| Max length bytes | x-max-length-bytes |
整数(字节) | 队列中 消息总字节数上限 | 超过时按照 Overflow behaviour 处理,适合大消息场景 |
| Maximum priority | x-max-priority |
整数 | 启用优先级队列时,队列可设置的 最大优先级值 | 消息优先级范围是 0 到这个值,优先级高的消息先被消费 |
| Leader locator | x-queue-leader-locator |
字符串(client-local、balanced) |
设置在集群节点上声明队列时,队列主节点(Leader)的选取规则 | client-local(默认):选择客户端所在节点作为Leader balanced:在节点间均衡Leader分布,用于 HA 队列优化 |
Quorum Queue(仲裁队列)
-
仲裁队列(Quorum Queue) 是 RabbitMQ 从3.8.0版本之后引入的一种现代队列类型,也是目前官方比较推荐的一种对列类型。未来有可能取代 经典队列 成为默认队列类型。
-
其基于 Raft 共识算法 实现 持久化、复制和高可用。它保证 数据安全性、可靠的主节点选举,即使在升级或集群波动期间也能保持高可用性。
-
仲裁队列支持 毒消息处理、至少一次死信投递 以及 AMQP 修改(AMQP.modified)的处理结果。
-
它适合 以数据安全为首要目标 的场景。与经典队列相比,Quorum是以牺牲很多高级队列特性为代价,来进一步保证消息在分布式环境下的高可靠。
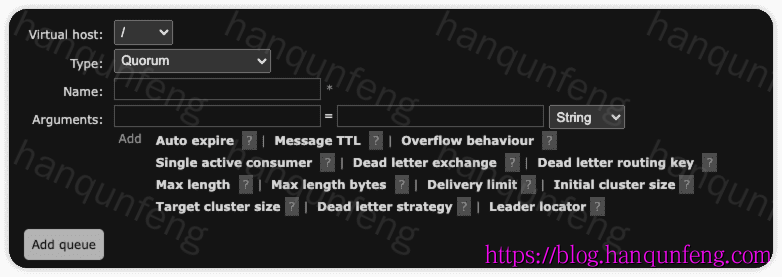
-
仲裁队列(Quorum Queue)的
Durability只能设置为 Durable(true)。Auto delete只能为 No(false)。 -
参数说明(每个版本可能都有变化,具体以页面显示为准)
| 参数名称 | 配置参数名 | 数据类型 | 作用说明 | 备注 / 使用场景 |
|---|---|---|---|---|
| Auto expire | x-expires |
整数(毫秒) | 队列在指定时间内无人使用(无消费者、无发布、无访问)时自动删除 | 节省资源,队列空闲过期时间 |
| Message TTL | x-message-ttl |
整数(毫秒) | 队列中消息的生存时间,超过时间后消息会被丢弃或转入死信队列 | 控制消息时效性 |
| Overflow behaviour | x-overflow |
字符串(drop-head 或 reject-publish) |
当队列达到最大长度时的处理方式 | drop-head:丢弃最早消息,reject-publish:拒绝新消息 |
| Single active consumer | x-single-active-consumer |
布尔值(true/false) | 是否启用单活消费者模式,一次只允许一个消费者消费队列 | 保证严格顺序消费 |
| Dead letter exchange (DLX) | x-dead-letter-exchange |
字符串 | 指定队列的死信交换机,用于接收无法消费或过期的消息 | 与 DLX 配合使用处理失败消息 |
| Dead letter routing key | x-dead-letter-routing-key |
字符串 | 消息转发到 DLX 时的路由键 | 灵活路由死信消息 |
| Max length | x-max-length |
整数 | 队列中最大消息条数 | 超过时按 Overflow behaviour 处理 |
| Max length bytes | x-max-length-bytes |
整数(字节) | 队列消息总字节数上限 | 超过时按 Overflow behaviour 处理 |
| Delivery limit | x-delivery-limit |
整数 | 消息允许投递的最大次数,超过后变为死信 | 控制消息重试次数 |
| Initial cluster size | x-quorum-initial-group-size |
整数 | 队列在创建时需要的最小节点数 | 用于保证仲裁队列的高可用性 |
| Target cluster size | x-quorum-target-group-size |
整数 | 队列运行时的目标节点数 | 当集群节点变化时,仲裁队列会尝试调整副本数量 |
| Dead letter strategy | x-dead-letter-strategy |
字符串(at-most-once、at-least-once) |
设置仲裁队列的死信处理策略 | 仅适用于 Quorum Queue。at-most-once(默认):消息最多投递一次,可能丢失。at-least-once:确保消息至少投递一次,必须将 Overflow behaviour 设置为 reject-publish,否则回退到 at-most-once。 |
| Leader locator | x-queue-leader-locator |
字符串(client-local、balanced) |
设置在集群节点上声明队列时,队列主节点(Leader)的选取规则 | client-local:选择客户端所在节点作为 Leader balanced:在节点间均衡 Leader 分布 |
-
Quorum Queues 和 Classic Queues 的功能对比如下:
| Feature | 中文含义 | Classic queues | Quorum queues | 说明 |
|---|---|---|---|---|
| Non-durable queues | 非持久化队列 | yes | no | Quorum queues 总是持久化,不支持非持久化 |
| Message replication | 消息复制 | no | yes | Quorum queues 内置消息复制,Classic queues 需镜像策略 |
| Exclusivity | 独占队列 | yes | no | Classic queues 支持独占队列,Quorum queues 不支持独占 |
| Per message persistence | 消息级持久化 | per message | always | Quorum queues 消息总是持久化 |
| Membership changes | 节点成员变更 | no | semi-automatic | Quorum queues 节点变化时半自动处理复制 |
| Message TTL (Time-To-Live) | 消息存活时间 | yes | yes | 两者都支持消息过期时间 |
| Queue TTL | 队列存活时间 | yes | partially | Quorum queues 的 lease 不会因重新声明而续期 |
| Queue length limits | 队列长度限制 | yes | yes | Quorum queues 支持长度限制,但 x-overflow=reject-publish-dlx 不支持 |
| Keeps messages in memory | 消息内存保存 | see Classic Queues | never | Quorum queues 消息总是写入磁盘,不保留在内存 |
| Message priority | 消息优先级 | yes | yes | 支持消息优先级 |
| Single Active Consumer | 单活消费者 | yes | yes | 支持单活消费者 |
| Consumer exclusivity | 独占消费者 | yes | no | Quorum queues 不支持独占消费者,需使用 Single Active Consumer |
| Consumer priority | 消费者优先级 | yes | yes | 支持消费者优先级 |
| Dead letter exchanges | 死信交换机 | yes | yes | 支持死信交换机 |
| Adheres to policies | 遵循策略 | yes | yes | 支持策略,但 Quorum queues 的部分策略行为不同 |
| Poison message handling | 毒消息处理 | no | yes | Quorum queues 支持毒消息处理 |
| Server-named queues | 服务器自动命名队列 | yes | no | Quorum queues 不支持服务器自动命名队列 |
Stream(流)
-
Stream 是RabbitMQ自 3.9.0 版本开始引入的一种新的数据队列类型。这种队列类型的消息是持久化到磁盘并且具备分布式备份的,更适合于消费者多,读消息非常频繁的场景。
-
Stream 的核心是以append-only只添加的日志来记录消息,整体来说,就是消息将以append-only的方式持久化到日志文件中,然后通过调整每个消费者的消费进度offset,来实现消息的多次分发。
-
Stream 不支持死信交换机,不支持处理毒消息。
-
实际上 Stream 不属于队列,流(Streams) 是一种 持久化、可复制的数据结构,功能上类似队列:从生产者缓冲消息供消费者读取。但它与队列有两个重要区别:
- 存储模型 – 流是 追加日志(append-only log),消息可以 重复读取直到过期。
- 消费模型 – 流提供 非破坏性消费语义(non-destructive consumer semantics),多个消费者可以多次读取同一条消息而不会删除它。
-
Stream 始终是持久化和复制的,保证数据安全。消费者可以通过 RabbitMQ 客户端库 或 专用二进制协议插件 读取流,其中插件方式可以 访问所有流特性 并提供 最佳性能。合理的客户端连接策略有助于提升 吞吐量和效率。
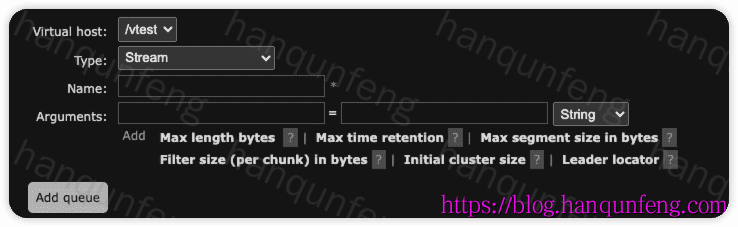
-
参数说明(每个版本可能都有变化,具体以页面显示为准)
| 参数名称 | 配置参数名 | 数据类型 | 作用说明 | 备注 / 使用场景 |
|---|---|---|---|---|
| Max length bytes | x-max-length-bytes |
整数(字节) | 流中允许存储的 最大数据总字节数 | 超过时流将停止接收新消息,适合控制存储容量 |
| Max time retention | x-max-age |
字符串(时间单位,例如 1h, 30m, 1d) |
设置流队列中消息的 最大保留时间,超过时间的消息会被删除 | 支持时间单位:Y=年, M=月, D=天, h=小时, m=分钟, s=秒。例如 "1h" 表示只保留最近 1 小时的消息,用于控制数据量和自动清理过期消息 |
| Max segment size in bytes | x-stream-max-segment-size |
整数(字节) | 流分段存储时的 每个段的最大字节数 | 控制单个文件段大小,有利于 I/O 性能和管理 |
| Filter size (per chunk) in bytes | x-stream-filter-size-bytes |
整数(字节) | 流内部 过滤索引每块的大小 | 用于加速消息定位和读取,影响内存使用和检索效率 |
| Initial cluster size | x-initial-cluster-size |
整数 | 流在创建时的 最小节点数 | 保证流的复制和高可用性 |
| Leader locator | x-queue-leader-locator |
字符串(client-local、balanced) |
设置在集群节点上声明流时,主节点(Leader)的选取规则 | client-local:客户端所在节点作为 Leader(默认)balanced:在节点间均衡 Leader 分布,用于优化 HA |
-
Classic Queue vs Stream Queue Feature Matrix
| Feature | 中文含义 | Classic queues | Stream queues | 说明 |
|---|---|---|---|---|
| Non-durable queues | 非持久化队列 | yes | no | Stream 队列总是持久化,不支持非持久化 |
| Exclusivity | 独占队列 | yes | no | Classic 队列支持独占,Stream 队列不支持独占 |
| Per message persistence | 消息级持久化 | per message | always | Stream 队列的消息总是持久化 |
| Membership changes | 节点成员变更 | no | manual | Stream 队列节点变更需要手动管理 |
| TTL | 消息存活时间 | yes | no (but see Retention) | Stream 队列没有消息 TTL,但可通过 Retention 控制过期 |
| Queue length limits | 队列长度限制 | yes | no (but see Retention) | Stream 队列没有固定长度限制,通过 Retention 控制数据量 |
| Keeps messages in memory | 消息内存保存 | see Classic Queues | never | Stream 队列消息不保存在内存中,只写入磁盘 |
| Message priority | 消息优先级 | yes | no | Stream 队列不支持消息优先级 |
| Consumer priority | 消费者优先级 | yes | no | Stream 队列不支持消费者优先级 |
| Dead letter exchanges | 死信交换机 | yes | no | Stream 队列不支持死信交换机 |
| Adheres to policies | 遵循策略 | yes | yes (see Retention) | Stream 队列支持策略,但主要通过 Retention 控制行为 |
| Reacts to memory alarms | 内存告警响应 | yes | no (uses minimal RAM) | Stream 队列使用最小内存,不触发内存告警 |
| Poison message handling | 毒消息处理 | no | no | Stream 队列不支持毒消息处理 |
-
我们可以激活
流插件来使用流的特有功能
1 | rabbitmq-plugins enable rabbitmq_stream rabbitmq_stream_management |
-
激活
流插件后,Stream队列的操作方式可以更高级,具体可以参考官方文档,作者在Java Client 示例中也给出了示例代码。
超级流(Super Streams)
-
超级流(Super streams) 是一种通过将一个大的流分区成更小的流来实现扩展的方式。它们与 单个消费者(Single Active Consumer) 集成,以在分区内保持消息顺序。超级流从 RabbitMQ 3.11 开始可用。
-
一个超级流是由多个普通流组成的逻辑流。它是一种通过 RabbitMQ Streams 来扩展发布和消费的方法:一个大型逻辑流被划分成多个分区流,将存储和流量分散到多个集群节点上。
-
超级流依然是一个逻辑实体:由于客户端库的智能化处理,应用程序会把它视为一个“大型”流。超级流的拓扑结构基于 AMQP 0.9.1 模型,也就是交换机(exchange)、队列(queue)和它们之间的绑定(binding)。
-
可以使用任何 AMQP 0.9.1 库或管理插件创建超级流的拓扑。它需要创建一个直连交换机(direct exchange)、分区流(partition streams),并将它们绑定在一起。
-
通过管理控制台创建超级流
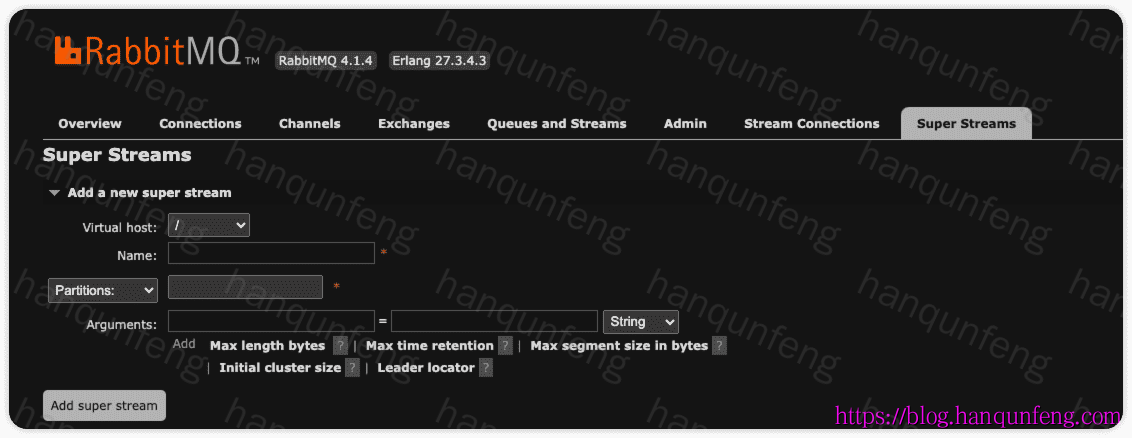
-
也可以通过命令创建超级流,以下是如何用命令创建一个包含 3 个分区的超级流:
1 | # rabbitmq-streams add_super_stream [-p <vhost>] <stream-name> [--partitions <number>] |
创建的Stream
创建的 Exchange,名称 sq_3
绑定关系
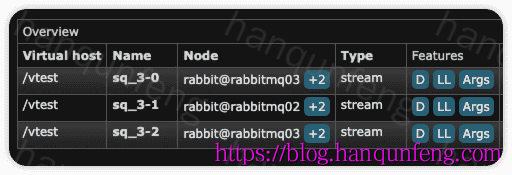

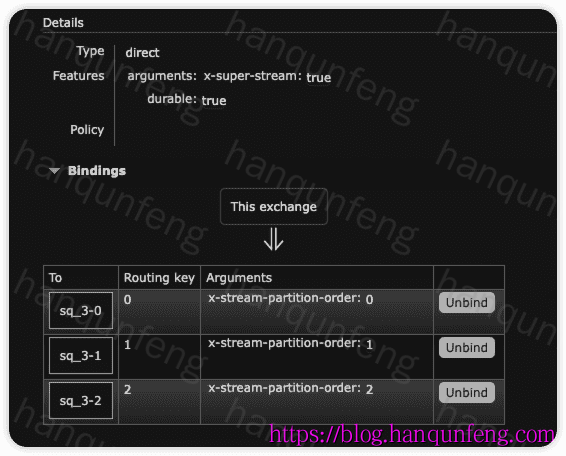
队列类型扩展
懒队列
-
从3.6.x版本到3.12.x版本,RabbitMQ提供了一种针对Classic Queue的优化配置,
lazy-mode,懒对列。懒队列会尽可能早的将消息内容保存到硬盘当中,并且只有在用户请求到时,才临时从硬盘加载到RAM内存当中。 -
默认情况下,RabbitMQ接收到消息时,会保存到内存以便使用,同时把消息写到硬盘。但是,消息写入硬盘的过程中,是会阻塞队列的。RabbitMQ虽然针对写入硬盘速度做了很多算法优化,但是在长队列中,依然表现不是很理想,所以就有了懒队列的出现。
-
懒队列会尝试尽可能早的把消息写到硬盘中。这意味着在正常操作的大多数情况下,RAM中要保存的消息要少得多。当然,这是以增加磁盘IO为代价的。
-
懒队列适合消息量大且长期有堆积的队列,可以减少内存使用,加快消费速度。但是这是以大量消耗集群的网络及磁盘IO为代价的。
-
从3.12往后的版本中,RabbitMQ 不再支持“惰性”模式,因为 经典队列 当前的特性就类似于以前的 懒队列。
死信队列
-
死信队列(Dead Letter Queue),新版中叫做 死信交换机(Dead Letter Exchange, DLX),是RabbitMQ对于未能正常消费的消息进行的一种补救机制,用于保存无法被正常处理的消息。当消息被消费者处理失败时,RabbitMQ会将消息发送到死信队列中,等待消费者处理。
-
死信队列也是一个普通的队列,同样可以在队列上声明消费者,继续对消息进行消费处理。
-
有以下几种情况,RabbitMQ会将一个正常消息转成死信
- 消息被拒绝(Message rejection)
- 由 AMQP 1.0 接收端使用 rejected 结果拒绝
- 由 AMQP 0.9.1 消费者使用 basic.reject 或 basic.nack,并且参数 requeue=false
- 消息过期(Message expiration)
- 消息超过其配置的 TTL(生存时间) 后过期。
- 队列长度超限(Queue length exceeded)
- 队列中的消息数量或总字节数达到配置的最大限制后,被丢弃的消息会死信化。
- 投递次数超限(仅适用于仲裁队列 Quorum Queue)
- 消息的投递次数超过了仲裁队列中配置的 delivery-limit。
- 消息被拒绝(Message rejection)
-
使用场景
- 你可以在队列上配置 死信交换机(DLX) 和 死信路由键(Dead Letter Routing Key)。
- 当消息成为死信时,会被 重新发布到 DLX,这样你可以:
- 做错误日志记录
- 进行失败消息重试
- 用于监控和告警
-
死信交换机的配置方法(How Dead Lettering is Configured)
- 在 RabbitMQ 中,任何队列都可以通过 客户端 或者 策略(policies) 来配置 死信交换机(DLX)。
- 配置时主要涉及两个核心参数:
| 配置参数名 | 说明 |
|---|---|
| dead-letter-exchange | 指定用于接收死信消息的 死信交换机名称 |
| dead-letter-routing-key | 指定死信消息重新发布时使用的 路由键(Routing Key) |
死信在转移到死信队列时,他的 routingkey 也会保存下来。但是如果配置了
x-dead-letter-routing-key这个参数的话,routingkey 就会被替换为配置的这个值。
-
在创建队列时,我们可以通过为队列添加
x-dead-letter-exchange和x-dead-letter-routing-key参数,来指定 死信交换机(DLX)和 死信路由键(Dead Letter Routing Key)。但是这样做很麻烦,每个队列都要单独配置,因此,我们可以使用 策略(policies) 来统一配置。
1 | # 仅指定死信交换机,这里交换机的名称是 my-dlx,交换机要提前创建好 |
-
参数说明:
| 部分 | 含义 |
|---|---|
rabbitmqctl |
RabbitMQ 的命令行管理工具 |
set_policy |
设置一个策略(Policy),用于动态配置交换机、队列或绑定的参数 |
DLX |
策略的名称,用户自定义,例如这里叫 DLX |
".*" |
正则表达式,匹配对象的名称。.* 表示匹配 所有队列,也可以指定具体队列名,比如 ^my-queue$ |
{"dead-letter-exchange":"my-dlx", "dead-letter-routing-key":"my-routing-key"} |
策略内容,这里设置了死信交换机名称和路由键: - dead-letter-exchange: 设置死信交换机名称为 my-dlx- dead-letter-routing-key: 设置路由键为 my-routing-key |
--apply-to queues |
指定策略作用对象为 队列(queues),而不是交换机(exchanges)或绑定(bindings) |
--priority 7 |
策略的优先级,值越大优先级越高。多个策略作用在同一对象时,优先级高的会覆盖低的 |
-
执行这条命令后:
- 所有队列都会自动带上
x-dead-letter-exchange=my-dlx和x-dead-letter-routing-key=my-routing-key配置。 - 队列中被拒绝、过期、超长或超过投递次数的消息会被重新发布到
my-dlx交换机,并使用my-routing-key作为路由键。
- 所有队列都会自动带上
-
消息被作为死信转移到死信队列后,会在Header当中增加⼀些消息。
1 | x-first-death-queue:该消息首次成为死信时所在的队列名称 |
延迟队列
-
延迟队列(Delayed Message Queue): 延迟队列是一种特殊类型的队列,用于延迟消息的投递。
-
RabbitMQ中,是不存在延迟队列的功能的,而通常如果要用到延迟队列,就会采用
TTL+死信队列的方式来实现。 -
延迟队列的实现原理:
- 创建一个普通队列,并设置队列的 TTL(x-message-ttl)参数,以及指定一个死信队列(x-dead-letter-exchange)
- 当消息的 TTL 到期时,消息会被自动从当前队列中删除,并进入死信队列。
- 为死信队列创建一个消费者,并监听死信队列,处理延迟消息。
优先级队列
-
优先级队列(Priority Queue): RabbitMQ 支持为经典队列(classic queues)添加“优先级”功能。启用“优先级”功能的经典队列通常被称为“优先级队列”(priority queues)。
-
RabbitMQ 支持 1 到 255 之间的优先级值,但强烈建议使用 1 到 5 之间的值。需要注意的是,优先级值越高,会消耗更多的 CPU 和内存资源,因为 RabbitMQ 在内部需要为每个优先级(从 1 到最大配置值)维护一个子队列。
-
只有经典队列支持通过参数
x-max-priority指定队列支持的最大优先级,且不支持 通过 策略(policies) 将经典队列声明为优先级队列。 -
发布消息时,可以通过参数
priority指定消息的优先级。是的,消息也是可以设置参数的。 -
优先级队列如何与消费者协同工作
- 若消费者连接到一个 空队列,然后消息陆续被发布,那么这些消息可能 不会 在队列中等待(即刚发布就被消费者接收),此时优先级功能没有机会上场。优先级是在消息排队(ready 消息)状态时才能体现其作用。
- 推荐在消费者端使用 basic.qos(prefetch) 设置(在 manual ack 模式下),以限制消费者同时处理的未确认消息数。这样能让优先级的分级效果更加明显,因为如果 prefetch 数量未满,高优先级消息可以先被取出。
-
注意事项
- 未设置
priority的消息 会被当作优先级 0 处理。若消息指定的优先级大于队列的最大值(x-max-priority),则该消息的优先级就是x-max-priority。 - TTL / 消息过期 (message expiration):即使设置了 TTL,过期的消息只会在队列头被检查。这意味着如果一个低优先级的消息在前面但还没过期,而高优先级的消息在后面,低优先级的消息可能会阻塞队列头,导致高优先级的消息被延迟。
- 队列最大长度限制 (max-length):如果队列设置了最大长度,队列会从头部 (head) 丢弃消息以维持长度限制。这可能导致高优先级消息也被丢弃,从而违背直觉。
- 未设置