











K8S 之 Pod
摘要
-
本文介绍 K8S 的 Pod,本文以 CentOS 8 为例。
Pod 介绍
-
Pod(缩写为 po) 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
-
Pod(就像在豌豆荚中)是一组(一个或多个) 容器,这些容器共享存储、网络、以及怎样运行这些容器的规约。
-
Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。
-
Kubernetes 集群中的 Pod 主要有两种用法:
- 运行单个容器的 Pod: "每个 Pod 一个容器"模型是最常见的 Kubernetes 用例,在这种情况下,可以将 Pod 看作单个容器的包装器,并且 Kubernetes 直接管理 Pod,而不是容器。
- 运行多个协同工作的容器的 Pod: Pod 可以封装由紧密耦合且需要共享资源的多个并置容器组成的应用,这些位于同一位置的容器构成一个内聚单元。
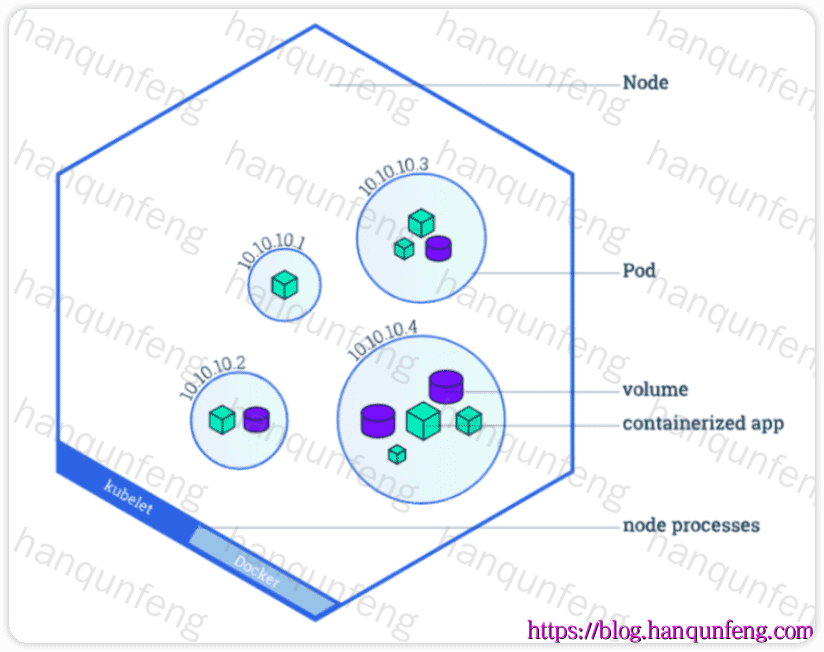
Pod 管理
Pod 创建
-
run创建
1 | kubectl run nginx --image=nginx |
-
pod 中至少包含两个容器,一个是业务容器,比如这里的 nginx,另一个是
pause容器,负责共享容器的网络,进程,存储等资源。
1 | # 通过 crictl ps 是看不到 pause 容器的,我们可以使用 ctr 命令查看,ctr 是 containerd 的命令行工具 |
pod.yaml 文件说明
-
因为 Pod 不支持扩缩容,所以日常使用时一般不会直接创建 Pod,而是创建
Deployment,DaemonSet等这些工作负载资源,这些后面会介绍到。 -
但我们这里还是要重点介绍一下 Pod 的 yaml 文件格式,因为它是后面所有资源创建的基础。
-
一个最基础的 Pod 配置如下:
1 | apiVersion: v1 # 必填。指定使用的 API 版本,Pod 是核心资源,使用 v1 |
-
Pod是用来配置容器的,我们在学习docker时知道,容器有非常多的配置项,比如端口、网络、存储等,而 pod 的配置项更丰富。
-
一个Pod的配置主要包含两大部分:
metadata和spec,每一项中包含的配置项非常多,这里只对常用的配置项进行说明,若要查看每个配置项的说明可以通过如下命令获取:
1 | # pod开头,配置项以 . 连接,例如: |
metadata
-
metadata 是 Pod 的元数据,比如 Pod 的名称、命名空间、标签、注解等。
1 | metadata: # 元数据部分 |
spec
-
spec 描述了 Pod 的配置信息,包括 Pod 的容器、存储、网络、资源限制、调度策略等
spec.containers
-
containers 描述了 Pod 中容器的配置信息,包括镜像、启动命令、环境变量、资源限制、卷挂载等
1 | spec: #必选,Pod中容器的详细定义 |
-
示例
1 | spec: # Pod 的具体规范 |
spec.containers.command | args
-
容器启动时执行的命令
-
默认情况下,容器启动时,会从镜像中获取命令并执行,如果这里配置了命令,则容器启动时,会执行这里的命令,而不是镜像中的命令
1 | spec: |
-
或者
1 | spec: |
-
或者
1 | spec: |
spec.restartPolicy
-
指在系统发生故障或意外停机时,系统或应用程序如何处理和恢复的策略
- Always:总是重启
- OnFailure:失败时重启
- Never:不重启
1 | spec: |
spec.terminationGracePeriodSeconds
-
Pod 删除时,系统给 Pod 留的时间,用于完成清理工作
-
宽限期为避免服务突然中断,造成事物不一致的问题,当容器运行完自己的任务后,会等待一段时间,然后优雅的退出
-
默认值为 30s,单位为秒
1 | spec: |
spec.volumes
-
Kubernetes 中的卷(volumes)是为了在容器之间共享数据,或将数据从容器持久化到外部存储。
emptyDir(最简单,Pod 生命周期内有效)
-
emptyDir 卷是一个没有名字的临时目录,Pod 创建时创建,Pod 删除时删除。
1 | spec: |
hostPath(挂载宿主机路径)
-
用于测试或非常了解宿主机结构的场景。生产不推荐。
1 | spec: |
configMap(挂载配置文件)
1 | spec: |
使用 PVC(挂载持久化存储)
1 | spec: |
spec.tolerations: Pod容忍策略
-
tolerations 是 Kubernetes Pod 中用来“容忍”某些 Node 节点的污点(Taints) 的字段。它允许 Pod 被调度到带有相应 Taint 的节点上。
-
默认情况下,Pod 会因为 Node 节点的 Taint 而不被调度。
-
比如一个 Node 有 NoSchedule 类型的 taint,而 Pod 没有设置对应的 toleration,该 Pod 就不会被调度到这个 Node 上。
-
示例: 容忍 key=value:NoSchedule 的 Taint
-
假设某节点打了如下污点(Taint):
1 | kubectl taint nodes node1 key=value:NoSchedule |
-
容忍该 Taint
1 | apiVersion: v1 |
-
在 Kubernetes 中,effect 有 三个可选值:
effect 值 |
含义 | 常见用途 |
|---|---|---|
NoSchedule |
节点上的污点会阻止 Pod 被调度到该节点,除非 Pod 有相应的 toleration。 | 最常用,例如 Master 节点的容忍。 |
PreferNoSchedule |
倾向于不调度 到该节点,但不是强制性的,调度器会尽量避免把 Pod 安排到该节点。 | 用于软约束,尽量不调度。 |
NoExecute |
不仅不调度新 Pod 到该节点,还会把当前节点上没有相应容忍度的 Pod 驱逐出去(eviction)。 |
节点异常自动驱逐,比如 not-ready。 |
spec.resources
-
Pod资源配额可以限制命名空间或项目中Pod使用的CPU、内存、存储等资源用量
-
CPU资源的约束和请求以豪核(m)为单位。在k8s中1m是最小的调度单元,CPU的一个核心可以看作1000m
如果你有2颗cpu,且每CPU为4核心,那么你的CPU资源总量就是8000
1 | spec: # Pod 的具体规范 |
-
如果有大量的容器需要设置资源配额,为每个Pod设置资源配额策略不方便且不好管理
-
可以以名称空间为单位(namespace),限制其资源的使用与创建,在该名称空间中创建的容器都会受到规则的限制。
LimitRange
-
对单个Pod内存、CPU进行配额
1 | apiVersion: v1 |
ResourceQuota
-
限制整个 namespace 的资源总量
1 | apiVersion: v1 |
spec.priorityClassName
-
Pod 的优先级,优先级就是为了保证重要的Pod被优先调度并运行
-
优先级策略:
- 非抢占优先:指的是在调度阶段优先进行调度分配,一旦容器调度完成就不可以抢占,资源不足时,只能等待
- 抢占优先:强制调度一个Pod,如果资源不足无法被调度,调度程序会抢占(删除)较低优先级的Pod的资 源,来保证高优先级Pod的运行
-
创建优先级
1 |
|
spec.nodeName | nodeSelector :Pod调度策略
-
在k8s中,调度是将Pod分配到合适的节点并运行的过程,kube-scheduler是默认调度器,是集群的核心组件。
-
调度器通过k8s的监测(Watch)机制来发现集群中尚未被调度到节点上的Pod,调度器依据调度原则将Pod分配到一个合适的节点上运行。
-
调度器给一个pod做调度包含两个步骤: 过滤 和 打分
- 过滤:首先要筛选出满足Pod所有的资源请求的节点,这里包含计算资源、内存、存储、网络、端口号等等,如果没有节点能满足Pod的需求,Pod将一直停留在Pending状态,直到调度器能够找到合适的节点运行它
- 打分:调度器将节点按照打分规则进行打分,然后按照分数进行排序,将分数最高的节点作为Pod的运行节点。如果存在多个得分最高的节点,调度器会从中随机选取一个。
-
Pod 支持两种调度策略:
nodeName和nodeSelector
spec.nodeName
-
指定 Pod 运行在指定名称的节点上
1 | spec: |
spec.nodeSelector
-
节点选择器,基于节点的标签进行调度
1 | spec: |
-
为节点设置标签
1 | # 所有资源都可以设置标签,语法为: kubectl label <资源> <资源名称> <标签key>=<标签value> |
spec.affinity
-
节点亲和性,用于控制 Pod 调度到具有特定标签的节点上,是 nodeSelector 的增强版本
| 类型 | 功能 | 示例用途 |
|---|---|---|
| Node Affinity | 控制调度到有指定标签的节点 | SSD、高内存节点 |
| Pod Affinity | 调度到和某些 Pod 一起的节点 | 微服务协同部署 |
| Pod Anti-Affinity | 避免和某些 Pod 一起的节点 | 高可用副本分散部署 |
节点亲和性(Node Affinity)
-
Pod 只能调度到具有标签
disktype=ssd的节点上
1 | apiVersion: v1 |
Pod 亲和性(Pod Affinity)
-
Pod 会被调度到 与标签为 app=web 的 Pod 所在同一节点(或拓扑层)上。
通常用于需要紧密协作的服务部署在一起(如同一机器内通信)。
1 | apiVersion: v1 |
Pod 反亲和性(Pod Anti-Affinity)
-
表示不能和 app=web 的 Pod 在同一节点上
常用于高可用部署,避免多个副本部署在同一个节点。
1 | apiVersion: v1 |
节点亲和性 (Node Affinity) 两种策略的对比
| 策略字段 | 含义 | 行为特点 | 场景适用 | 是否强制 |
|---|---|---|---|---|
requiredDuringSchedulingIgnoredDuringExecution |
“必须满足”亲和性规则 | Pod 调度时必须满足条件,不满足则不调度;调度后节点变化不触发驱逐 | 硬性约束,比如必须调度到有 GPU 的节点 | ✅ 强制 |
preferredDuringSchedulingIgnoredDuringExecution |
“尽量满足”亲和性规则 | Pod 调度时优先考虑满足条件的节点,但条件不满足时仍然可以调度到其他节点;调度后同样不会强制迁移 | 软性倾向,比如尽量调度到 SSD 节点,但实在没有也可调度 | ❌ 非强制 |
spec.securityContext: 设置安全上下文
runAsUser: 设置运行用户
-
默认情况下容器都是以root用户运行的,但是很多应用需要以非root用户运行,比如 Elasticsearch 。
1 | apiVersion: v1 |
privileged: 是否以特权方式运行
-
容器与宿主机是共享内核的,默认情况下,容器用户是不允许修改内核参数的,但是可以通过设置
privileged: true来允许容器以特权方式运行。
1 | apiVersion: v1 |
allowPrivilegeEscalation: 是否可以提权(SUID)
-
s位:当某可执行命令的所有者的位置上有s位时,那么当普通用户执行这个命令时将具有所有者的权限。
1 | apiVersion: v1 |
查看 Pod
1 | # 查看 Pod,默认显示 default 命名空间下的 Pod |
查看 Pod 详情
-
当 pod 运行错误时,可以通过该命令查看 pod 的详情,找到错误原因
1 | kubectl describe pod <pod-name> |
进入容器
1 | # kubectl exec -it <pod-name> -n <namespace-name> -- <command> |
删除 Pod
1 | kubectl delete pod <pod-name> |
-
长时间处于 Terminating 状态的 Pod,这类 Pod 大概率是由于所在节点异常(失联、被重装、或 kubelet 停止),导致 Kubernetes 控制面无法与该 Pod 对应的 kubelet 通信完成删除操作,从而卡在 Terminating 状态,其实它已经死了,但 etcd 里的记录一直保留着。
1 |
|
访问 Pod
-
我们刚刚创建了一个nginx的pod,该如何访问呢?
1 | # 获取pod的ip |
-
暂时我们还不能通过节点的 IP 访问 Pod,因为 Pod 运行在容器网络中,等我后面讲解 deployment 和 service 之后,会介绍如何通过 service 访问
一个 Pod 运行多个容器
-
yaml 文件
1 | apiVersion: v1 |
-
运行 pod
1 | kubectl apply -f multi_pod.yaml |
-
查看运行结果
1 | # 这里看到,READY 里有两个,表示两个容器都运行成功 |
-
访问nginx和tomcat
1 | # 访问nginx,ngxin默认端口是80 |
-
进入容器执行命令
1 | # 进入nginx容器,-c 指定容器名称 |