











一文搞懂ELK
摘要
-
本文介绍如何在linux下安装LogStash和FileBeat
-
通过示例讲解ELK的经典架构和高并发架构的实现过程
-
LogStash版本8.17.3,FileBeat版本8.17.3
-
Elasticsearch版本8.17.3,linux下安装Elasticsearch
-
Kibana版本8.17.3,linux下安装Kibana
-
Elasticsearch集群搭建,linux下安装Elasticsearch集群
Logstash概述
-
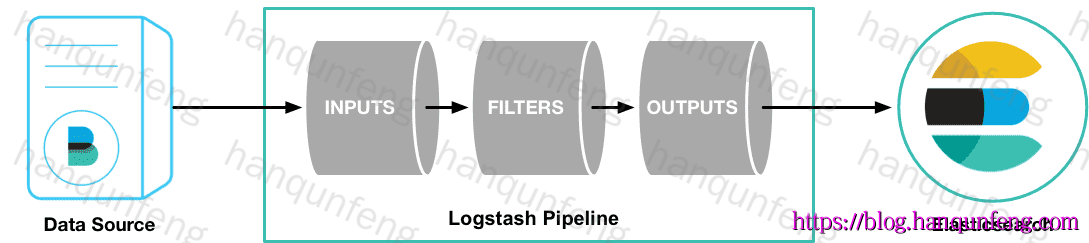
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的存储库中。
-
Logstash数据传输原理
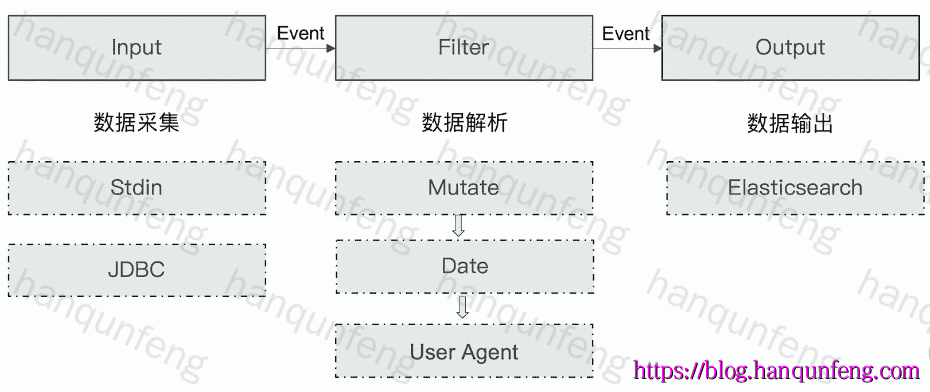
1 | 1.数据采集与输入:Logstash支持各种输入选择,能够以连续的流式传输方式,轻松地从日志、指标、Web应用以及数据存储中采集数据。 |
-
Logstash通过管道完成数据的采集与处理,管道配置中包含input、output和filter(可选)插件,input和output用来配置输入和输出数据源、filter用来对数据进行过滤或预处理。
Logstash下载安装
-
下载地址:https://www.elastic.co/cn/downloads/past-releases#logstash
-
选择对应的版本:这里选择当前的最新版
LogStash 8.17.3,之后选择对应的操作系统LINUX X86_64
1 | wget https://artifacts.elastic.co/downloads/logstash/logstash-8.17.3-linux-x86_64.tar.gz |
-
下载完成后解压到
/usr/local/logstash目录下,解压命令如下:
1 | mkdir /usr/local/logstash |
-
elasticsearch和kibana都不能用root用户启动,为了统一管理,logstash也使用这个用户(非必要)
-
创建用户
elastic,并设置密码,这一步我们在安装elasticsearch的时候已经配置过了,这里就不再赘述了
1 | useradd elastic |
-
修改logstash安装目录的用户权限
1 | chown -R elastic:elastic /usr/local/logstash |
-
切换到elastic用户下执行命令
1 | # 切换用户 |
-
运行一个简单的测试
1 | # -e: 直接把配置放在命令中,这样可以有效快速进行测试 |
-
也可以通过配置文件启动logstash
1 | # vim test.conf |
1 | ./bin/logstash -f ./test.conf |
Logstash插件
Input Plugins
https://www.elastic.co/guide/en/logstash/8.17/input-plugins.html
-
一个 Pipeline可以有多个input插件
1 | - Stdin / File |
Filter Plugins
https://www.elastic.co/guide/en/logstash/8.17/filter-plugins.html
-
Filter Plugin可以对Logstash Event进行各种处理,例如解析,删除字段,类型转换
1 | - Date: 日期解析 |
Output Plugins
https://www.elastic.co/guide/en/logstash/8.17/output-plugins.html
-
将Event发送到特定的目的地,是 Pipeline 的最后一个阶段。常见 Output Plugins:
1 | - Elasticsearch |
Codec Plugins
https://www.elastic.co/guide/en/logstash/8.17/codec-plugins.html
-
将原始数据decode成Event;将Event encode成目标数据,内置的Codec Plugins:
1 | - Line / Multiline |
FileBeat概述
-
Beats 是一个免费且开放的平台,集合了多种单一用途的数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
-
FileBeat 专门用于转发和收集日志数据的轻量级采集工具。它可以作为代理安装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到的日志转发到Elasticsearch或者Logstash。
logstash vs FileBeat
-
Logstash是在jvm上运行的,资源消耗比较大。而FileBeat是基于golang编写的,功能较少但资源消耗也比较小,更轻量级。
-
Logstash 和Filebeat都具有日志收集功能,Filebeat更轻量,占用资源更少
-
Logstash 具有Filter功能,能过滤分析日志
-
一般结构都是Filebeat采集日志,然后发送到消息队列、Redis、MQ中,然后Logstash去获取,利用Filter功能过滤分析,然后存储到Elasticsearch中
-
FileBeat和Logstash配合,实现背压机制。当将数据发送到Logstash或 Elasticsearch时,Filebeat使用背压敏感协议,以应对更多的数据量。如果Logstash正在忙于处理数据,则会告诉Filebeat 减慢读取速度。一旦拥堵得到解决,Filebeat就会恢复到原来的步伐并继续传输数据。
FileBeat下载和安装
-
下载地址:https://www.elastic.co/cn/downloads/past-releases#filebeat
-
选择对应的版本:这里选择当前的最新版
FileBeat 8.17.3,之后选择对应的操作系统LINUX X86_64
1 | wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.17.3-linux-x86_64.tar.gz |
-
下载完成后解压到
/usr/local/filebeat目录下,解压命令如下:
1 | mkdir /usr/local/filebeat |
-
修改logstash安装目录的用户权限
1 | chown -R elastic:elastic /usr/local/filebeat |
-
切换到elastic用户下执行命令
1 | # 切换用户 |
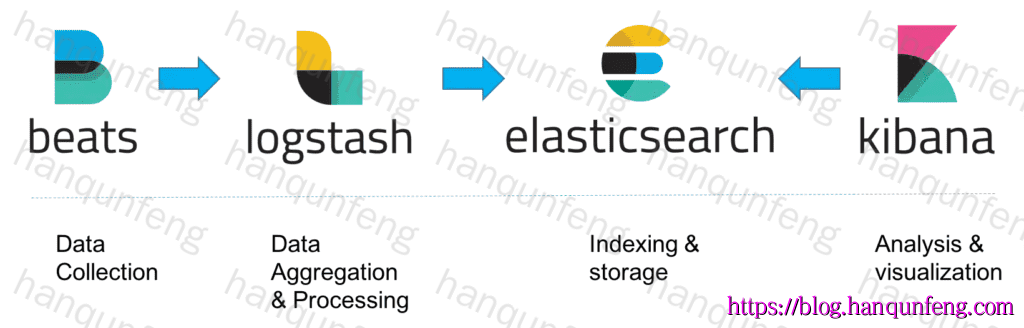
经典的ELK架构
-
Filebeat日志收集:Filebeat作为轻量级的日志收集代理,部署在客户端上,消耗资源少,能够高效地收集日志数据。
-
Logstash数据处理:Logstash作为数据处理管道,负责将Filebeat收集的日志数据进行过滤、转换等操作,然后发送到Elasticsearch进行存储。
-
Elasticsearch存储与搜索:Elasticsearch是一个基于Lucene的分布式搜索和分析引擎,提供强大的数据存储和搜索能力。
-
Kibana可视化:Kibana为Elasticsearch提供Web可视化界面,允许用户通过图表、仪表盘等方式直观地查看和分析日志数据。
-
适用场景:经典的ELK架构主要适用于数据量较小的开发环境。然而,由于缺少消息队列的缓冲机制,当Logstash或Elasticsearch出现故障时,可能存在数据丢失的风险。
一个经典ELK架构示例
FileBeat采集Nginx服务器日志并发送到Logstash
-
创建配置文件
filebeat-nginx.yml,将其保存到Filebeat安装目录下的conf目录下。
1 | # 因为Nginx的access.log日志都是以IP地址开头的,所以我们需要修改下匹配字段。 |
-
为FileBeat的用户分配日志目录的读取权限
1 | # 使用 setfacl命令为elastic用户分配日志目录的读取权限 |
-
启动FileBeat
1 | ./filebeat -e -c conf/filebeat-nginx.yml |
-
在启动filebeat时可能会遇到如下错误
1 | Exiting: error loading config file: config file ("conf/filebeat-nginx.yml") can only be writable by the owner but the permissions are "-rw-rw-r--" (to fix the permissions use: 'chmod go-w /usr/local/filebeat/filebeat-8.17.3-linux-x86_64/conf/filebeat-nginx.yml') |
-
因为安全原因不要其他用户写的权限,去掉写的权限就可以了
1 | chmod go-w conf/filebeat-nginx.yml |
配置Logstash接收FileBeat收集的数据并打印
-
创建配置文件
logstash-nginx.conf,将其保存到Logstash安装目录下的config目录下。
1 | # 进入logstash安装目录 |
-
测试logstash配置是否正确
1 | bin/logstash -f config/logstash-nginx.conf --config.test_and_exit |
-
启动logstash
1 | # reload.automatic:修改配置文件时自动重新加载 |
利用Logstash过滤器解析日志
-
从打印结果看到包含了大量的无关数据,此时可以利用Logstash过滤器解析日志,这里使用
Grok插件 -
Grok是一种将非结构化日志解析为结构化的插件。这个工具非常适合用来解析系统日志、Web服务器日志、MySQL或者是任意其他的日志格式。
-
Grok是通过模式匹配的方式来识别日志中的数据,可以把Grok插件简单理解为升级版本的正则表达式。它拥有更多的模式,默认Logstash拥有120个模式。如果这些模式不满足我们解析日志的需求,我们可以直接使用正则表达式来进行匹配。
-
grok模式的语法是:
1 | %{SYNTAX:SEMANTIC} |
-
匹配nginx日志
1 | # nginx access日志格式 |
-
匹配Grok模式是个非常繁琐的过程,我们可以使用Kibana来进行可视化的Grok调试
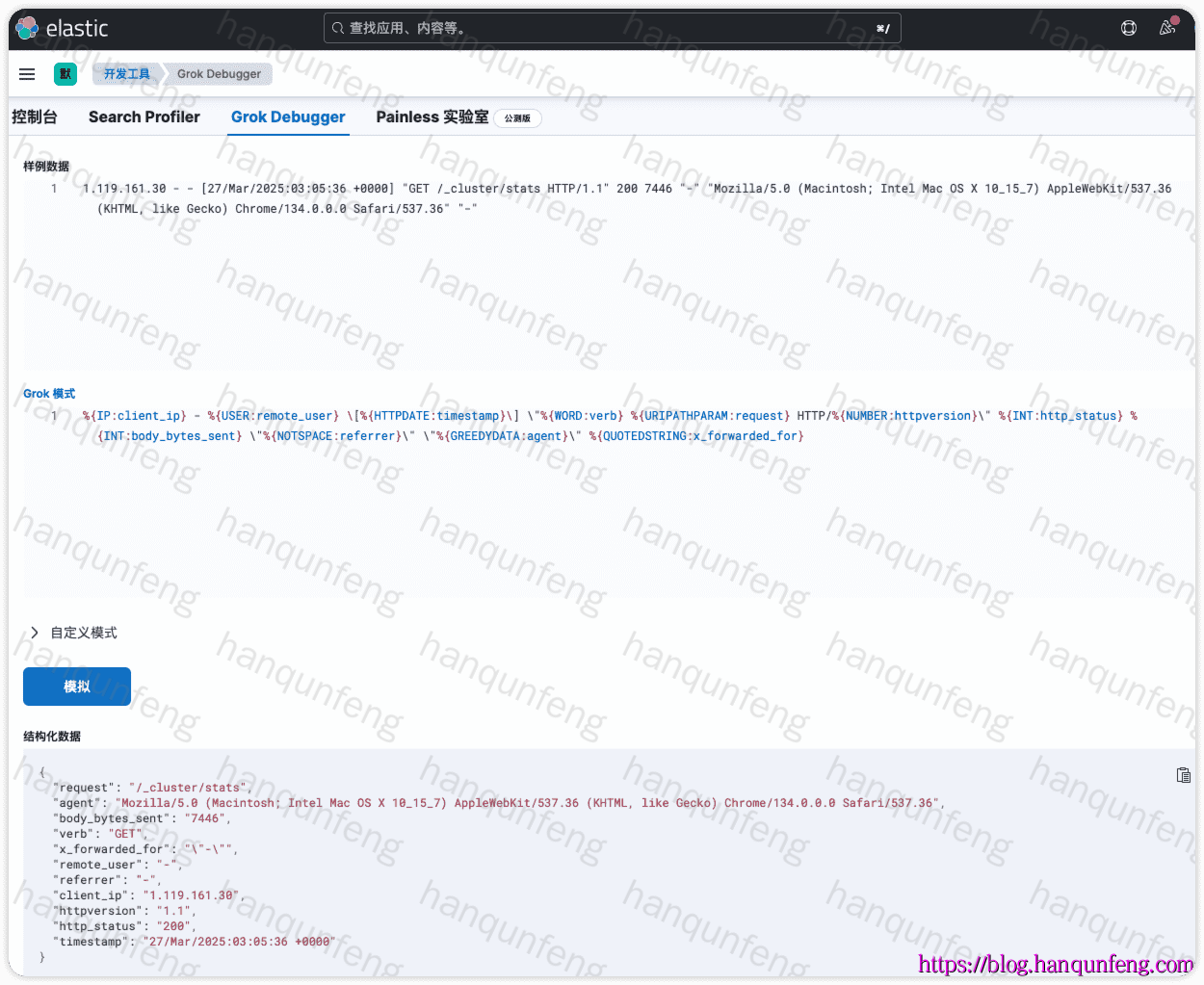
-
grok配置
1 | grok { |
使用mutate插件过滤掉不需要的字段
-
除了nginx日志本身的格式外,logstash还会打印许多我们不需要的字段,此时可以使用
mutate插件来过滤掉不需要的字段。
1 | mutate { |
使用Date插件对时间进行格式转换
1 | date { |
完整的Logstash配置
1 | # 进入logstash安装目录 |
-
重新启动logstash后得到如下结果:
1 | { |
将结果输出到ES
1 | # 在输出配置中添加ES输出配置 |
-
如果需要开启证书校验,可以通过如下方法进行配置
- 获取 Elasticsearch 的 SSL 证书:
1
2# 从 Elasticsearch 的配置文件或证书文件路径中获取证书(通常是 .pem 或 .crt 文件)。
/usr/local/elasticsearch/elasticsearch-8.17.3/config/certs/http_ca.crt- 导入证书到 Java 信任库:注意这里要导入到启动Logstash的JAVA进程的信任库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44# logstash的jdk路径,默认在logstash的安装目录下
cd /usr/local/logstash/logstash-8.17.3/jdk
bin/keytool -importcert -alias es-cert -keystore /usr/local/logstash/logstash-8.17.3/logstash.keystore -file /usr/local/elasticsearch/elasticsearch-8.17.3/config/certs/http_ca.crt
# 输出
Enter keystore password: # 输入密码 这里是123456
Re-enter new password:
Owner: CN=Elasticsearch security auto-configuration HTTP CA
Issuer: CN=Elasticsearch security auto-configuration HTTP CA
Serial number: 89d5c501a2efd5d45a6ee5e08daa16bd605d8c28
Valid from: Thu Mar 20 08:53:26 UTC 2025 until: Sun Mar 19 08:53:26 UTC 2028
Certificate fingerprints:
SHA1: DE:73:0C:EC:46:59:69:83:52:7C:C4:CC:6B:65:EC:B6:31:BE:10:22
SHA256: 3F:14:1C:16:DF:C6:E1:65:89:4B:C1:67:20:84:B2:20:DC:DD:22:FF:E0:21:16:D5:1A:C1:80:03:CF:AA:5A:1D
Signature algorithm name: SHA256withRSA
Subject Public Key Algorithm: 4096-bit RSA key
Version: 3
Extensions:
#1: ObjectId: 2.5.29.35 Criticality=false
AuthorityKeyIdentifier [
KeyIdentifier [
0000: 25 EF BA 81 AE 5E 14 1C 7E FF A1 87 12 F8 D0 2E %....^..........
0010: 3A D7 54 5F :.T_
]
]
#2: ObjectId: 2.5.29.19 Criticality=true
BasicConstraints:[
CA:true
PathLen: no limit
]
#3: ObjectId: 2.5.29.14 Criticality=false
SubjectKeyIdentifier [
KeyIdentifier [
0000: 25 EF BA 81 AE 5E 14 1C 7E FF A1 87 12 F8 D0 2E %....^..........
0010: 3A D7 54 5F :.T_
]
]
Trust this certificate? [no]: yes # yes确认
Certificate was added to keystore-
配置 Logstash 使用信任库
1
2
3
4
5
6
7
8
9
10
11
12output {
elasticsearch {
index => "nginx_access_log_%{+YYYY-MM}" # 索引名,按月分隔
hosts => ["https://10.250.0.239:9200"] # ES地址
user => "elastic" # ES用户名
password => "123456" # ES密码
ssl => true # 是否启用SSL,因为这里是https访问ES
ssl_certificate_verification => true # 启用证书校验
ssl_truststore_path => "/usr/local/logstash/logstash-8.17.3/logstash.keystore" # 指定信任库路径
ssl_truststore_password => "123456" # 信任库密码
}
}
整合消息队列+Nginx的ELK架构
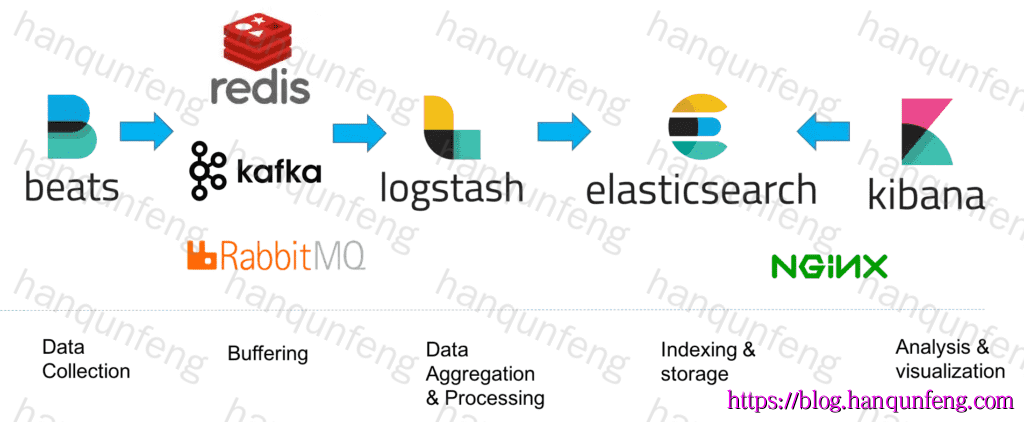
-
消息队列:引入消息队列作为缓冲机制,确保即使在Logstash或Elasticsearch出现故障时,日志数据也不会丢失。消息队列能够均衡网络传输,降低数据丢失的可能性。
-
Nginx:Nginx作为高性能的Web和反向代理服务器,可以进一步优化整个系统的性能和可用性。它可以在负载均衡、缓存等方面发挥作用,提升用户访问体验。
-
扩展性:由于引入了消息队列和Nginx等组件,整个架构的扩展性得到增强。可以根据实际需求动态调整各组件的资源分配和部署规模。
-
适用场景:整合消息队列+Nginx的架构主要适用于生产环境,特别是需要处理大数据量的场景。它能够确保数据的安全性和完整性,同时提供高性能的日志处理和可视化分析服务。
-
总结来说就是
- filebeat将采集的日志发送到Redis\RabbitMQ\Kafka等
- Logstash再从Redis\RabbitMQ\Kafka中读取日志数据,并进行解析后发送到ES中。
- ES集群使用nginx进行负载均衡,以实现高可用和高性能。具体实现方法查看:linux下安装Elasticsearch集群
基于Redis的ELK架构示例
filebeat将采集的日志发送到Redis
-
创建配置文件
filebeat-nginx-to-redis.yml,将其保存到Filebeat安装目录下的conf目录下。
1 | # 因为Nginx的access.log日志都是以IP地址开头的,所以我们需要修改下匹配字段。 |
-
启动Filebeat,并查看日志输出。
1 | ./filebeat -e -c conf/filebeat-nginx-to-redis.yml |
-
查看Redis中的数据
1 | $ redis-cli -h 10.250.0.214 -p 6379 -a 123456 |
Logstash从Redis中读取日志并写入Elasticsearch
-
创建配置文件
logstash-nginx-redis-to-es.conf,将其保存到Logstash安装目录下的conf目录下。
1 | # 进入logstash安装目录 |
-
测试logstash配置是否正确
1 | bin/logstash -f config/logstash-nginx-redis-to-es.conf --config.test_and_exit |
-
启动logstash
1 | # reload.automatic:修改配置文件时自动重新加载 |