











AWS-EKS-19--Autoscaling 之 Karpenter
摘要
-
本文介绍EKS集群Autoscaling 之 Karpenter
-
参考资料:
Karperter是什么?
-
Karpenter 是一个开源集群自动缩放器,可以自动为不可安排的pod提供新节点。Karpenter评估了挂起的pod的聚合资源需求,并选择运行它们的最佳实例类型。它将自动扩展或终止没有任何非daemonset pod的实例,以减少浪费。它还支持整合功能,该功能将积极移动pod,并用更便宜的版本删除或替换节点,以降低集群成本。
-
Karpenter 是aws为 k8s 构建的能用于生产环境的开源的工作节点动态调度控制器。
-
在Karpenter推出之前,Kubernetes用户主要依靠Amazon EC2 Auto Scaling组和Kubernetes Cluster Autoscaler(CAS)来动态调整其集群的计算容量。
-
相较于传统的 Cluster Autoscaler 工具,Karpenter 具有调度速度快、更灵活、资源利用率高等众多优势,另外,Karpenter与Kubernetes版本没有那么紧密耦合(像CAS那样),所以其是 EKS 自动扩缩容的首选方案,两者的比较可以参考下图。
| 特 性 | Cluster Autoscaler | Karpenter |
|---|---|---|
| 资源管理 | Cluster Autoscaler基于现有节点的资源利用率采用反应性方法来扩展节点。 | Karpenter基于未调度的Pod的当前资源需求采取主动方法来进行节点预配。 |
| 节点管理 | Cluster Autoscaler根据当前工作负载的资源需求来管理节点,使用预定义的自动缩放组。 | Karpenter根据自定义预配程序的配置来扩展、预配和管理节点。 |
| 扩展 | Cluster Autoscaler更专注于节点级别的扩展,这意味着它可以有效地添加更多的节点以满足需求的增加。 但这也意味着它在缩减资源方面可能不太有效。 | Karpenter根据特定的工作负载需求提供更有效和精细的扩展功能。换句话说,它根据实际使用情况进行扩展。它还允许用户指定特定的扩展策略或规则以满足其需求。 |
| 调度 | 使用Cluster Autoscaler进行调度更简单,因为它是根据工作负载的当前需求设计的进行扩展或缩减。 | Karpenter可以根据可用区和资源需求有效地调度工作负载。它可以尝试通过Spot实例来优化成本,但它不会知道你已经在aws帐号中做的任何承诺,如RI(预留实例)或Savings Plans(储蓄计划)。 |
Karpenter 运行环境准备
设置环境变量
1 | # aws认证profile |
创建 Karpenter 的 node 需要的 role
-
1.创建role
1 | $ echo '{ |
-
2.给这个 role 添加 policy
1 | $ aws iam attach-role-policy --role-name "KarpenterNodeRole-${CLUSTER_NAME}" \ |
-
3.把 role 授予 EC2 的 instance profile
1 | $ aws iam create-instance-profile \ |
创建 Karpenter controller 需要的 role
-
1.创建role
1 | $ cat << EOF > controller-trust-policy.json |
-
2.为role配置policy
1 | $ cat << EOF > controller-policy.json |
为所有子网和安全组添加标签
-
1.为节点组内的子网打标签
1 | $ for NODEGROUP in $(aws eks list-nodegroups --cluster-name ${CLUSTER_NAME} --query 'nodegroups' --output text) |
-
2.给托管节点组的运行模版的安全组打标签
1 | # 获取节点组 |
更新 aws-auth ConfigMap
-
将上面为node创建的role加入到集群权限
1 | $ kubectl edit configmap aws-auth -n kube-system |
-
编辑后完整的内容如下:
1 | apiVersion: v1 |
-
查看授权信息
1 | $ eksctl get iamidentitymapping --cluster eks-lexing |
部署 Karpenter
-
1.设置环境变量
1 | # 当前最新版是 v0.29.1 , https://github.com/aws/karpenter/releases |
-
2.创建 karpenter.yaml 模版
1 | $ helm template karpenter oci://public.ecr.aws/karpenter/karpenter --version ${KARPENTER_VERSION} \ |
-
3.设置节点亲和性,编辑
karpenter.yaml,找到karpenter deployment的亲和性配置,修改为如下内容,注意这里ng-4d9024eb要替换为你的${NODEGROUP}。关节K8s节点亲和性的介绍可以参考官方文档亲和性与反亲和性
1 | affinity: |
为其他关键集群工作负载设置nodeAffinity
- 例如 CoreDNS,Controller,CNI,CSI 和 Operator 等,这些 workload 对弹性要求不高但是稳定性要求比较高,建议部署在创建EKS时的节点组运行。
- 为这些关键负载设置nodeAffinity
1 | affinity: |
- 比如设置
k edit deploy ebs-csi-controller -n kube-system,添加好nodeAffinity后保存,然后查看对应的pod是否重启成功,如果一只处于pending状态,可以试着重启
1 | $ k scale deploy ebs-csi-controller --replicas 0 -n kube-system |
- 设置好所有关键负载后,可以重启一下 karpenter
1 | $ k scale deploy karpenter --replicas 0 -n karpenter |
-
查看 karpenter 日志是否正常
1 | $ k logs deployments/karpenter -f -n karpenter |
-
4.部署 karpenter 及其 相关资源
1 | # 创建Namespace |
-
5.创建默认的供应者(provisioner)
- Provisioner与AWSNodeTemplate是karpenter在K8s中的自定义资源。
Provisioner对 Karpenter 可创建的节点以及可在这些节点上运行的 Pod 设置约束。如果没有配置至少一个Provisioner,Karpenter 将不会执行任何操作。- 关于
Provisioner支持的配置项可以参考官方文档,比如下面就限制了被管控的节点必须符合两个条件:
1.实例类别必须在[c, m, r]中
2.实例的生成代次必须大于2。比如 实例类型为c1.xxx,m1.xxx,m2.xxx就不符合要求AWSNodeTemplate节点模板启用AWS特定设置的配置。关于AWSNodeTemplate支持的配置项可以参考官方文档,比如默认节点关联的存储为20G gp3,如果要修改为40G可以在spec下指定如下内容,先创建后编辑也可以,但只有修改后新创建的节点才会使用新的配置。
1
2
3
4
5
6blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeType: gp3
volumeSize: 40Gi
deleteOnTermination: true-
Provisioner需要与AWSNodeTemplate关联使用,通过在Provisioner的providerRef中指定AWSNodeTemplate的name进行关联,一个AWSNodeTemplate可以被多个Provisioner关联。 -
配置的每个
Provisioner均由 Karpenter 循环遍历。在Provisioner中定义污点以限制可以在 Karpenter 创建的节点上运行的 Pod。建议创建互斥的Provisioner。因此任何 Pod 都不应该匹配多个Provisioner。如果匹配多个Provisioner,Karpenter将使用权重最高的Provisioner。关于K8s中污点的介绍可以参考官方文档污点和容忍度 -
下面是一个最基本的
Provisioner定义,你可以根据需要创建自己的Provisioner,可以参考官方文档或者查看provisioner examples中的示例。
1 | # 创建 default Provisioner |
-
查看 karpenter 状态
1 | $ k get pod -n karpenter |
-
查看 karpenter 日志是否正常
1 | $ k logs deployments/karpenter -f -n karpenter |
-
karpenter创建新的节点时不会在原有的节点组中进行,所以为了摆脱从节点组添加的实例,我们可以将节点组缩小到最小大小
1 | # 如果您有一个多AZ节点组,我们建议至少2个实例。 |
-
关停Cluster Autoscaler(CAS)
如果EKS中已经开启了CAS,则安装Karpenter后需要关闭CAS
1 | $ kubectl scale deploy/cluster-autoscaler -n kube-system --replicas=0 |
测试
-
查看当前node信息
1 | $ k get node |
-
采用 AWS-EKS-18--Autoscaling 之 Cluster Autoscaler(CAS) 中的测试方法,将deploy的副本数设置为50,过一会查看node情况
1 | # 可以看到node数量已经变为3了,说明扩容成功 |
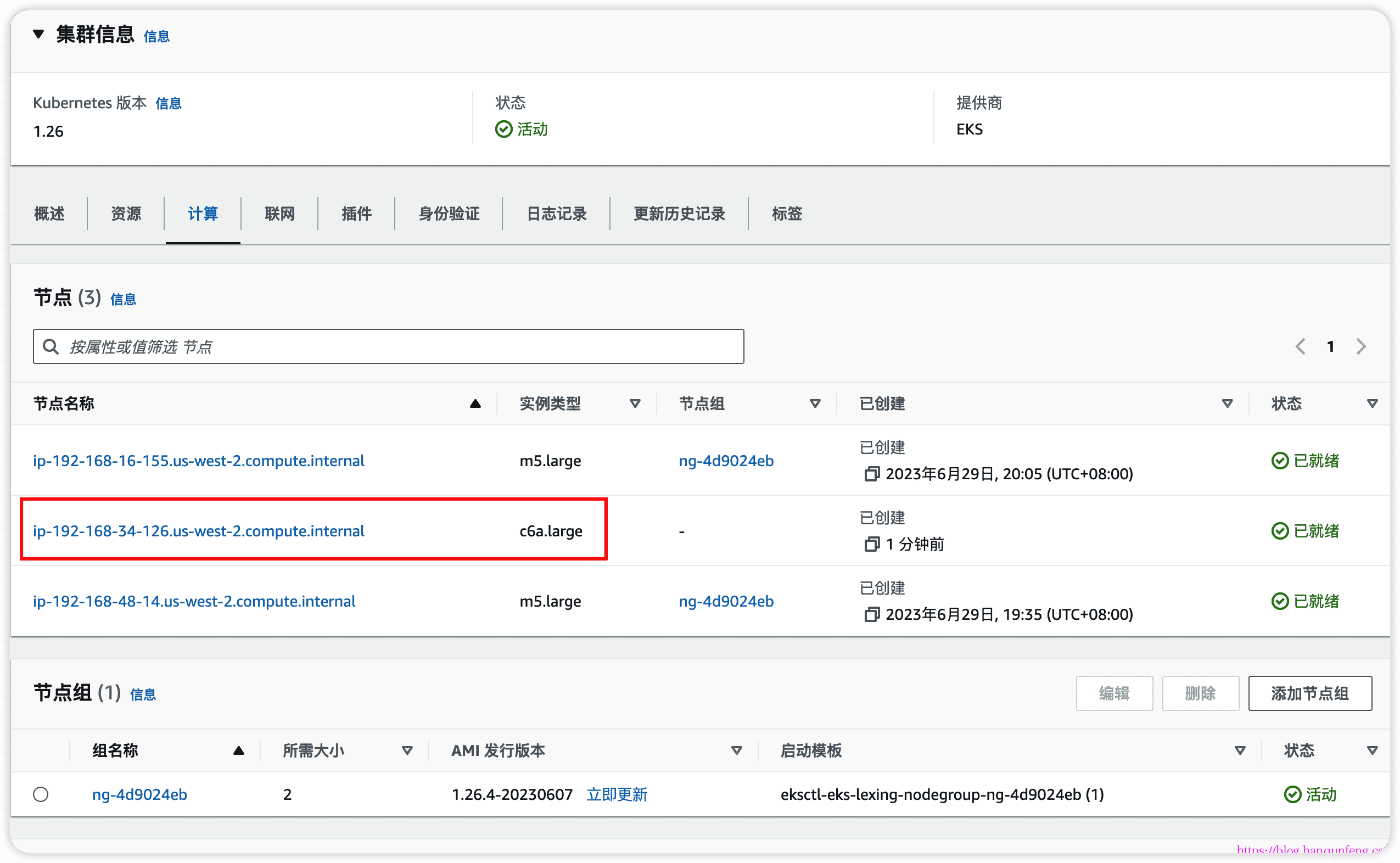
-
缩容测试用的deploy,副本数设置为1,过一会发现node节点并没有被终止,这是为什么呢?
默认情况下,Karpenter不会主动终止节点,需要为其设置终止节点的方式,参考Karpenter官方文档Deprovisioning部分
-
在
Provisioner中设置节点终止的方式spec.ttlSecondsAfterEmpty: 当最后一个工作负载(非守护程序集)pod停止在节点上运行时,Karpenter会注意到。从那时起,Karpenter在提供程序中等待ttlSecondsAfterEmpty设置的秒数,然后Karpenter请求删除节点。此功能可以通过删除不再用于工作负载的节点来降低成本。spec.ttlSecondsUntilExpired: Karpenter 将根据Provisioner的ttlSecondsUntilExpired值将节点注释为过期,并在节点生存了设定秒数后取消配置节点。节点过期的一种用例是定期回收节点。spec.consolidation.enabled: 实现整合,通过删除不需要的节点和缩减无法删除的节点的规模来降低集群成本。与ttlSecondsAfterEmpty参数互斥。
1 | # 编辑 default provisioner,并为其指定 spec.ttlSecondsAfterEmpty: 30,表示空闲超过30秒则终止节点。 |
1 | apiVersion: karpenter.sh/v1alpha5 |
-
等待30秒后查看node情况,新创建的node已经成功终止
1 | $ k get node |
-
创建和终止节点的过程可以通过日志进行观察
1 | $ k logs deployments/karpenter -f -n karpenter |
小贴士
当Karpenter管理的Node节点由于某种原因不可用时(比如我们在AWS控制台终止了EC2或通过命令行删除节点k delete node nodeName),Karpenter会立刻为我们创建一个新的Node节点,并在其上重启Pod。
参考资料
从Cluster Autoscaler迁移
EKS Cluster Autoscaler 迁移 Karpenter 实践
Karpenter Best Practices