











Java并发编程--JUC并发容器
摘要
-
本文介绍并发容器相关技术
-
本文基于
jdk1.8
并发容器
-
Java的集合容器框架中,主要有四大类别:
List、Set、Queue、Map,大家熟知的这些集合类ArrayList、LinkedList、HashMap等这些容器都是非线程安全的。 -
为了保证线程安全,所以java提供了
同步容器,可以简单地理解为通过synchronized来实现同步的容器,比如Vector、Hashtable以及SynchronizedList等容器,这样做的代价是削弱了并发性,当多个线程共同竞争容器级的锁时,吞吐量就会降低。 -
因此为了解决同步容器的性能问题,所以才有了
并发容器,java.util.concurrent包中提供了多种并发类容器:
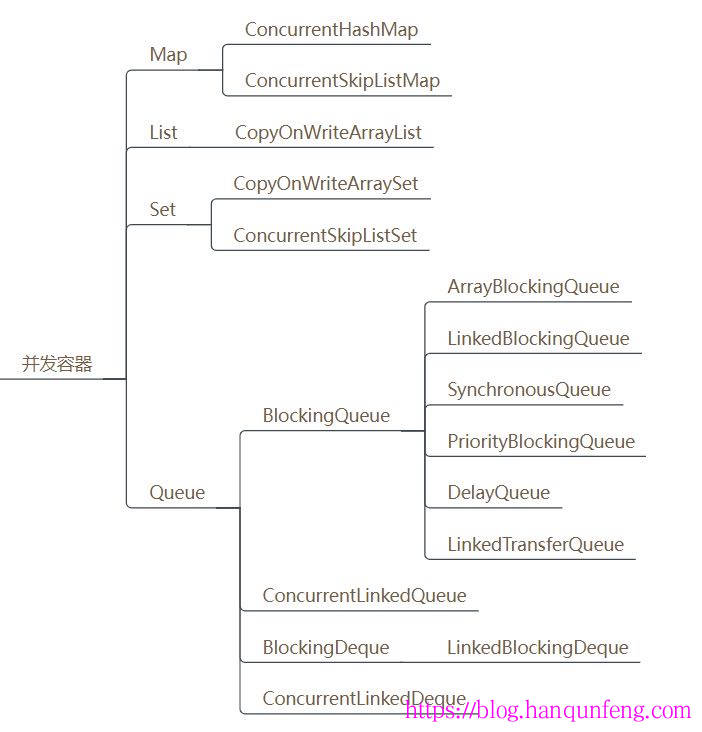
| 并发容器 | 对应的非并发容器 | 代替的同步容器 | 实现原理 | 应用场景 |
|---|---|---|---|---|
| CopyOnWriteArrayList | ArrayList | Vector、synchronizedList | CopyOnWriteArrayList 内部使用了一种称为“写时复制”的机制。当需要进行写操作时,它会创建一个新的数组,并将原始数组的内容复制到新数组中,然后进行写操作。一旦修改完成,新的副本会替代原始数组,成为新的数据源。 因此,读操作不会被写操作阻塞,读操作返回的结果可能不是最新的,但是对于许多应用场景来说,这是可以接受的。此外,由于读操作不需要加锁,因此它可以支持更高的并发度。 需要注意的是,虽然副本会替代原始数组,但是这个替代并不是立即发生的。在修改操作期间,读操作仍然可能会访问原始数组。只有当修改完成后,才会将新的副本设置为源数组。 |
1. 读多写少的场景由于 CopyOnWriteArrayList 的读操作不需要加锁,因此它非常适合在读多写少的场景中使用。例如,一个读取频率比写入频率高得多的缓存,使用 CopyOnWriteArrayList 可以提高读取性能,并减少锁竞争的开销。 2. 不需要实时更新的数据由于 CopyOnWriteArrayList 读取的数据可能不是最新的,因此它适合于不需要实时更新的数据。例如,在日志应用中,为了保证应用的性能,日志记录的操作可能被缓冲,并不是实时写入文件系统,而是在某个时刻批量写入。这种情况下,使用 CopyOnWriteArrayList 可以避免多个线程之间的竞争,提高应用的性能。 注意:由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致 young gc 或者full gc,谨慎使用 |
| CopyOnWriteArraySet | HashSet | synchronizedSet | 基于CopyOnWriteArrayList实现,其唯一的不同是在add时调用的是CopyOnWriteArrayList的addIfAbsent方法,其遍历当前Object数组,如Object数组中已有了当前元素,则直接返回,如果没有则放入Object数组的尾部,并返回。 | 同CopyOnWriteArrayList |
| ConcurrentHashMap | HashMap | Hashtable、synchronizedMap | 在JDK1.8之前,ConcurrentHashMap使用分段锁以在保证线程安全的同时获得更大的效率。 JDK1.8开始舍弃了分段锁,使用自旋+CAS+synchronized关键字来实现同步。 这样做的好处: 1.节省内存空间 ,分段锁需要更多的内存空间,而大多数情况下,并发粒度达不到设置的粒度,竞争概率较小,反而导致更新的长时间等待(因为锁定一段后整个段就无法更新了) 2.提高GC效率。 |
1.共享数据的线程安全:在多线程编程中,如果需要进行共享数据的读写,可以使用 ConcurrentHashMap 保证线程安全。 2. 缓存:ConcurrentHashMap 的高并发性能和线程安全能力,使其成为一种很好的缓存实现方案。在多线程环境下,使用 ConcurrentHashMap 作为缓存的数据结构,能够提高程序的并发性能,同时保证数据的一致性。 |
| ConcurrentSkipListMap | TreeMap | synchronizedSortedMap(TreeMap) | 基于Skip list(跳表)实现的有序映射(Map)数据结构,是一种可以代替平衡树的数据结构,默认是按照Key值升序的。 | ConcurrentSkipListMap适用于需要高并发性能、支持有序性和区间查询的场景,能够有效地提高系统的性能和可扩展性。 |
| ConcurrentLinkedQueue | LinkedList | LinkedBlockingQueue | ConcurrentLinkedQueue 基于无锁算法和乐观并发策略,旨在提供高效的并发操作。它使用一个单向链表数据结构来存储元素,并且保持了先进先出(FIFO)的顺序。 ConcurrentLinkedQueue 是一个无界队列,它没有固定的容量限制。可以根据需要动态地增长或缩小链表的长度。 需要注意的是,ConcurrentLinkedQueue 并不适合在迭代过程中进行修改操作,因为它的结构在并发情况下可能会发生变化。 |
1.高并发环境:ConcurrentLinkedQueue 适用于需要高并发性能和线程安全的场景。由于它采用无锁算法和乐观并发策略,可以在高并发环境下提供较高的吞吐量。 2.生产者-消费者模式:ConcurrentLinkedQueue 在实现生产者-消费者模式时非常有用。生产者线程可以将元素添加到队列的尾部,而消费者线程可以从队列的头部获取元素,实现了解耦和并发处理。 3.任务调度:ConcurrentLinkedQueue 可以作为任务调度的数据结构,用于存储待执行的任务。多个线程可以从队列中获取任务并执行,从而实现任务的并发处理。 |
| ConcurrentLinkedDeque | LinkedList | 无 | 与ConcurrentLinkedQueue 相比 ConcurrentLinkedDeque 是基于双向链表实现的并发双端队列。它支持在队头和队尾进行插入和移除操作,保持了元素的先进先出顺序。 | ConcurrentLinkedDeque 适用于需要双端操作的并发场景,例如生产者-消费者模式中的多线程同时插入和移除元素的场景。 |
CopyOnWriteArrayList
| 方法 | 描述 |
|---|---|
int size() |
返回列表中的元素数量。 |
boolean isEmpty() |
检查列表是否为空。 |
boolean contains(Object o) |
检查列表是否包含指定元素。 |
Iterator<E> iterator() |
返回一个迭代器,用于遍历列表中的元素。 |
boolean add(E e) |
将元素添加到列表末尾。 |
boolean remove(Object o) |
从列表中移除指定元素的第一个匹配项。 |
boolean containsAll(Collection<?> c) |
检查列表是否包含指定集合中的所有元素。 |
boolean addAll(Collection<? extends E> c) |
将指定集合中的所有元素添加到列表末尾。 |
boolean addAll(int index, Collection<? extends E> c) |
将指定集合中的所有元素插入到列表的指定位置。 |
boolean removeAll(Collection<?> c) |
移除列表中与指定集合中的元素相匹配的所有元素。 |
boolean retainAll(Collection<?> c) |
仅保留列表中与指定集合中的元素相匹配的元素,移除其他元素。 |
void clear() |
清空列表中的所有元素。 |
E get(int index) |
返回列表中指定位置的元素。 |
E set(int index, E element) |
用指定元素替换列表中指定位置的元素,并返回原来的元素。 |
void add(int index, E element) |
在列表的指定位置插入指定元素。 |
E remove(int index) |
移除列表中指定位置的元素,并返回被移除的元素。 |
int indexOf(Object o) |
返回指定元素在列表中首次出现的位置索引,如果不存在,则返回 -1。 |
int lastIndexOf(Object o) |
返回指定元素在列表中最后一次出现的位置索引,如果不存在,则返回 -1。 |
小贴士
迭代器的 fail-fast 与 fail-safe 机制
- 在 Java 中,迭代器(Iterator)在迭代的过程中,如果底层的集合被修改(添加或删除元素),不同的迭代器对此的表现行为是不一样的,可分为两类:Fail-Fast(快速失败)和 Fail-Safe(安全失败)。
fail-fast 机制
- fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。例如:当某一个线程A通过 iterator 去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生 fail-fast 事件。
- 在 java.util 包中的集合,如 ArrayList、HashMap 等,它们的迭代器默认都是采用 Fail-Fast 机制。
- fail-fast解决方案
- 方案一:在遍历过程中所有涉及到改变modCount 值的地方全部加上synchronized 或者直接使用Collection#synchronizedList,这样就可以解决问题,但是不推荐,因为增删造成的同步锁可能会阻塞遍历操作。
- 方案二:使用CopyOnWriteArrayList 替换 ArrayList,推荐使用该方案(即fail-safe)。
fail-safe机制
- 任何对集合结构的修改都会在一个复制的集合上进行,因此不会抛出ConcurrentModificationException。在 java.util.concurrent 包中的集合,如CopyOnWriteArrayList、ConcurrentHashMap 等,它们的迭代器一般都是采用 Fail-Safe 机制。
- 缺点:
- 采用 Fail-Safe 机制的集合类都是线程安全的,但是它们无法保证数据的实时一致性,它们只能保证数据的最终一致性。在迭代过程中,如果集合被修改了,可能读取到的仍然是旧的数据。
- Fail-Safe 机制还存在另外一个问题,就是内存占用。由于这类集合一般都是通过复制来实现读写分离的,因此它们会创建出更多的对象,导致占用更多的内存,甚至可能引起频繁的垃圾回收,严重影响性能
CopyOnWriteArraySet
| 方法 | 描述 |
|---|---|
int size() |
返回集合中的元素数量。 |
boolean isEmpty() |
检查集合是否为空。 |
boolean contains(Object o) |
检查集合是否包含指定的元素。 |
boolean add(E e) |
将指定元素添加到集合中。 |
boolean remove(Object o) |
从集合中移除指定元素。 |
void clear() |
清空集合中的所有元素。 |
Iterator<E> iterator() |
返回在集合上进行迭代的迭代器。 |
boolean containsAll(Collection<?> c) |
检查集合是否包含指定集合中的所有元素。 |
boolean addAll(Collection<? extends E> c) |
将指定集合中的所有元素添加到集合中。 |
boolean removeAll(Collection<?> c) |
从集合中移除指定集合中包含的所有元素。 |
boolean retainAll(Collection<?> c) |
仅保留集合中包含在指定集合中的元素,移除其他元素。 |
CopyOnWriteArraySet与CopyOnWriteArrayList的区别
-
数据结构类型:CopyOnWriteArraySet 是一个基于数组的集合,而 CopyOnWriteArrayList 是一个基于数组的列表。
-
元素的唯一性:CopyOnWriteArraySet 保证集合中的元素是唯一的,不允许重复元素的存在。而 CopyOnWriteArrayList 允许列表中存在重复元素。
-
集合与列表的特性:CopyOnWriteArraySet 实现了 Set 接口,它是一个无序的集合,不保留插入顺序。CopyOnWriteArrayList 实现了 List 接口,它是一个有序的列表,保留插入顺序。
代码示例
1 | // 创建 CopyOnWriteArraySet 实例 |
ConcurrentHashMap
| 方法 | 描述 |
|---|---|
int size() |
返回映射中的键值对数量。 |
boolean isEmpty() |
检查映射是否为空。 |
boolean containsKey(Object key) |
检查映射是否包含指定的键。 |
boolean containsValue(Object value) |
检查映射是否包含指定的值。 |
V get(Object key) |
获取与指定键关联的值。 |
V put(K key, V value) |
将指定的键值对添加到映射中。 |
V remove(Object key) |
从映射中移除指定键的映射关系,并返回对应的值。 |
void clear() |
清空映射中的所有键值对。 |
Set<K> keySet() |
返回映射中所有键的集合。 |
Collection<V> values() |
返回映射中所有值的集合。 |
Set<Map.Entry<K, V>> entrySet() |
返回映射中所有键值对的集合。 |
V putIfAbsent(K key, V value) |
当指定的键尚未映射到值时,将指定的键值对添加到映射中。 |
boolean remove(Object key, Object value) |
从映射中移除指定键值对。 |
boolean replace(K key, V oldValue, V newValue) |
用新的值替换指定键的旧值,仅当当前值与指定的旧值相等时才替换。 |
V replace(K key, V value) |
用指定值替换指定键的值。 |
JDK1.7 中的ConcurrentHashMap
在jdk1.7及其以下的版本中,结构是用Segments数组 + HashEntry数组 + 链表实现的
JDK1.8中的ConcurrentHashMap
jdk1.8抛弃了Segments分段锁的方案,而是改用了和HashMap一样的结构操作,也就是数组 + 链表+ 红黑树结构,比jdk1.7中的ConcurrentHashMap提高了效率,在并发方面,使用了cas +synchronized的方式保证数据的一致性
-
链表转化为红黑树需要满足2个条件:
- 1.链表的节点数量大于等于树化阈值8
- 2.Node数组的长度大于等于最小树化容量值64
代码示例
1 | import java.util.concurrent.ConcurrentHashMap; |
ConcurrentSkipListMap
ConcurrentSkipListMap 和 ConcurrentHashMap 是 Java 中用于并发访问的映射数据结构,它们之间有一些区别
-
数据结构:ConcurrentSkipListMap 是基于跳表(Skip List)的数据结构实现,而 ConcurrentHashMap 是基于
数组 + 链表+ 红黑树的数据结构实现。 -
排序性:ConcurrentSkipListMap 是有序映射,按照键的自然顺序或自定义的比较器对键进行排序。而 ConcurrentHashMap 是无序映射,不保证键值对的顺序。
-
并发访问性能:在高度并发的情况下,ConcurrentSkipListMap 在读取方面的性能较好,因为它支持并发读取操作,并且有序结构使得读取更高效。而 ConcurrentHashMap 在写入方面的性能较好,因为它使用
cas +synchronized来支持并发写入操作。 -
内存占用:通常情况下,ConcurrentSkipListMap 的内存占用比 ConcurrentHashMap 更高,因为它需要额外的存储空间来维护跳表结构。
-
功能特性:由于有序性的特点,ConcurrentSkipListMap 提供了一些与顺序相关的方法,如
firstKey()、lastKey()、subMap()等。
| 方法 | 描述 |
|---|---|
K firstKey() |
返回映射中的第一个键。 |
K lastKey() |
返回映射中的最后一个键。 |
ConcurrentNavigableMap<K, V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) |
返回一个视图,该视图包含映射中键的子范围。 |
ConcurrentNavigableMap<K, V> headMap(K toKey, boolean inclusive) |
返回一个视图,该视图包含映射中小于(或小于等于)给定键的部分。 |
ConcurrentNavigableMap<K, V> tailMap(K fromKey, boolean inclusive) |
返回一个视图,该视图包含映射中大于(或大于等于)给定键的部分。 |
ConcurrentNavigableMap<K, V> descendingMap() |
返回与此映射相反的顺序的视图。 |
ConcurrentNavigableSet<K> navigableKeySet() |
返回包含映射中所有键的并发可导航集合。 |
ConcurrentNavigableSet<K> descendingKeySet() |
返回与此映射中的键相反顺序对应的并发可导航集合。 |
代码示例
1 | import java.util.concurrent.ConcurrentSkipListMap; |
小贴士
跳表
跳表(Skip List)是一种用于实现有序集合的数据结构,它的设计灵感来自于平衡树。跳表通过使用多层链表结构,每一层链表按照升序排列,并且每一层链表都是前一层链表的子集。这样的结构允许在搜索、插入和删除元素时具有较高的效率。
跳表的核心思想是通过建立索引层来加快搜索的速度。最底层是原始链表,每个节点都包含一个元素。而上层的链表是通过原始链表中的一部分节点创建的。在每一层中,节点以一定的概率被提升到更高层,从而形成了跨越多个层级的链接。
跳表的主要优点是在具有合理的设计和维护下,可以在平均情况下以 O(log n) 的时间复杂度执行搜索、插入和删除操作。这是因为每一层的节点数量是下一层的节点数量的一半,从而形成了一种对数级别的分布。
以下是跳表的主要操作:
-
搜索:从顶层开始,沿着每一层的链表进行比较,如果目标元素大于当前节点的值,则在当前层继续向右移动;如果目标元素小于当前节点的值,则退回到下一层继续比较。直到找到目标元素或者无法再继续向右或下移动。
-
插入:通过搜索找到插入位置后,在每一层链表中插入新节点,并更新相应的索引层。
-
删除:通过搜索找到要删除的节点位置后,在每一层链表中删除节点,并更新相应的索引层。
跳表的实现相对简单,它提供了在有序集合中进行快速搜索和更新的高效方式。然而,它的空间复杂度相对于平衡树较高,因为需要维护额外的索引层。跳表在并发环境下也需要考虑同步的问题,以确保数据的一致性和线程安全性。
总结而言,跳表通过建立多层索引结构,在有序集合中实现了较快的搜索、插入和删除操作。它是一种简单而高效的数据结构,在一些场景中可以作为替代平衡树的选择。
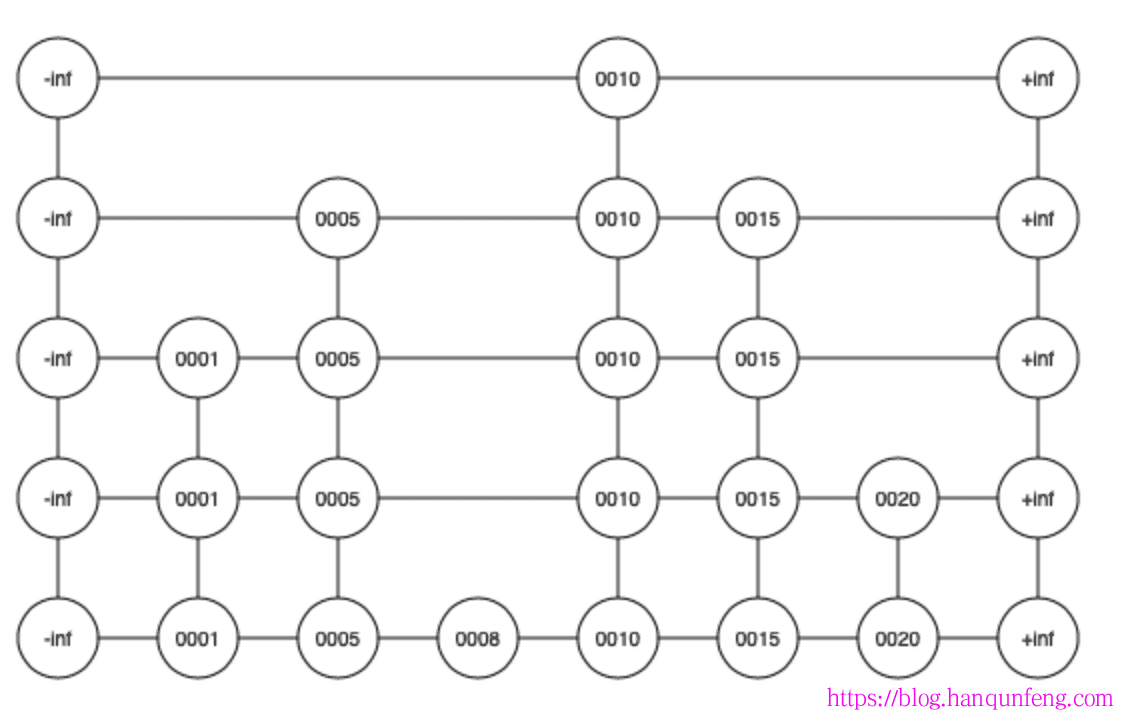
ConcurrentLinkedQueue
| 方法 | 描述 |
|---|---|
boolean add(E e) |
将指定元素添加到队列的尾部。 |
boolean offer(E e) |
将指定元素添加到队列的尾部。 |
E poll() |
获取并移除队列的头部元素。 |
E peek() |
获取队列的头部元素,但不移除。 |
int size() |
返回队列中的元素数量。 |
boolean isEmpty() |
检查队列是否为空。 |
boolean contains(Object o) |
检查队列是否包含指定元素。 |
boolean remove(Object o) |
从队列中移除指定元素的第一个匹配项。 |
void clear() |
移除队列中的所有元素。 |
boolean containsAll(Collection<?> c) |
检查队列是否包含指定集合中的所有元素。 |
boolean addAll(Collection<? extends E> c) |
将指定集合中的所有元素添加到队列的尾部。 |
boolean removeAll(Collection<?> c) |
从队列中移除包含在指定集合中的所有元素。 |
boolean retainAll(Collection<?> c) |
仅保留队列中包含在指定集合中的元素,移除其他元素。 |
代码示例
1 | import java.util.concurrent.ConcurrentLinkedQueue; |
ConcurrentLinkedDeque
| 方法 | 描述 |
|---|---|
void addFirst(E e) |
将指定元素插入到双端队列的开头。 |
void addLast(E e) |
将指定元素插入到双端队列的末尾。 |
boolean offerFirst(E e) |
将指定元素插入到双端队列的开头。如果成功则返回 true,否则返回 false。 |
boolean offerLast(E e) |
将指定元素插入到双端队列的末尾。如果成功则返回 true,否则返回 false。 |
E pollFirst() |
获取并移除双端队列的开头元素。 |
E pollLast() |
获取并移除双端队列的末尾元素。 |
E peekFirst() |
获取双端队列的开头元素,但不移除。 |
E peekLast() |
获取双端队列的末尾元素,但不移除。 |
boolean removeFirstOccurrence(Object o) |
从双端队列中移除首次出现的指定元素。 |
boolean removeLastOccurrence(Object o) |
从双端队列中移除最后一次出现的指定元素。 |
void push(E e) |
将元素推入双端队列的开头。 |
E pop() |
从双端队列的开头弹出一个元素。 |
boolean remove(Object o) |
从双端队列中移除指定元素的第一个匹配项。 |
boolean contains(Object o) |
检查双端队列是否包含指定元素。 |
int size() |
返回双端队列中的元素数量。 |
boolean isEmpty() |
检查双端队列是否为空。 |
void clear() |
移除双端队列中的所有元素。 |
boolean containsAll(Collection<?> c) |
检查双端队列是否包含指定集合中的所有元素。 |
boolean addAll(Collection<? extends E> c) |
将指定集合中的所有元素添加到双端队列的末尾。 |
代码示例
1 | import java.util.concurrent.ConcurrentLinkedDeque; |